Building AI-Powered Search with GPT-5.5 Instant: From Query Understanding to Result Ranking and Personalization
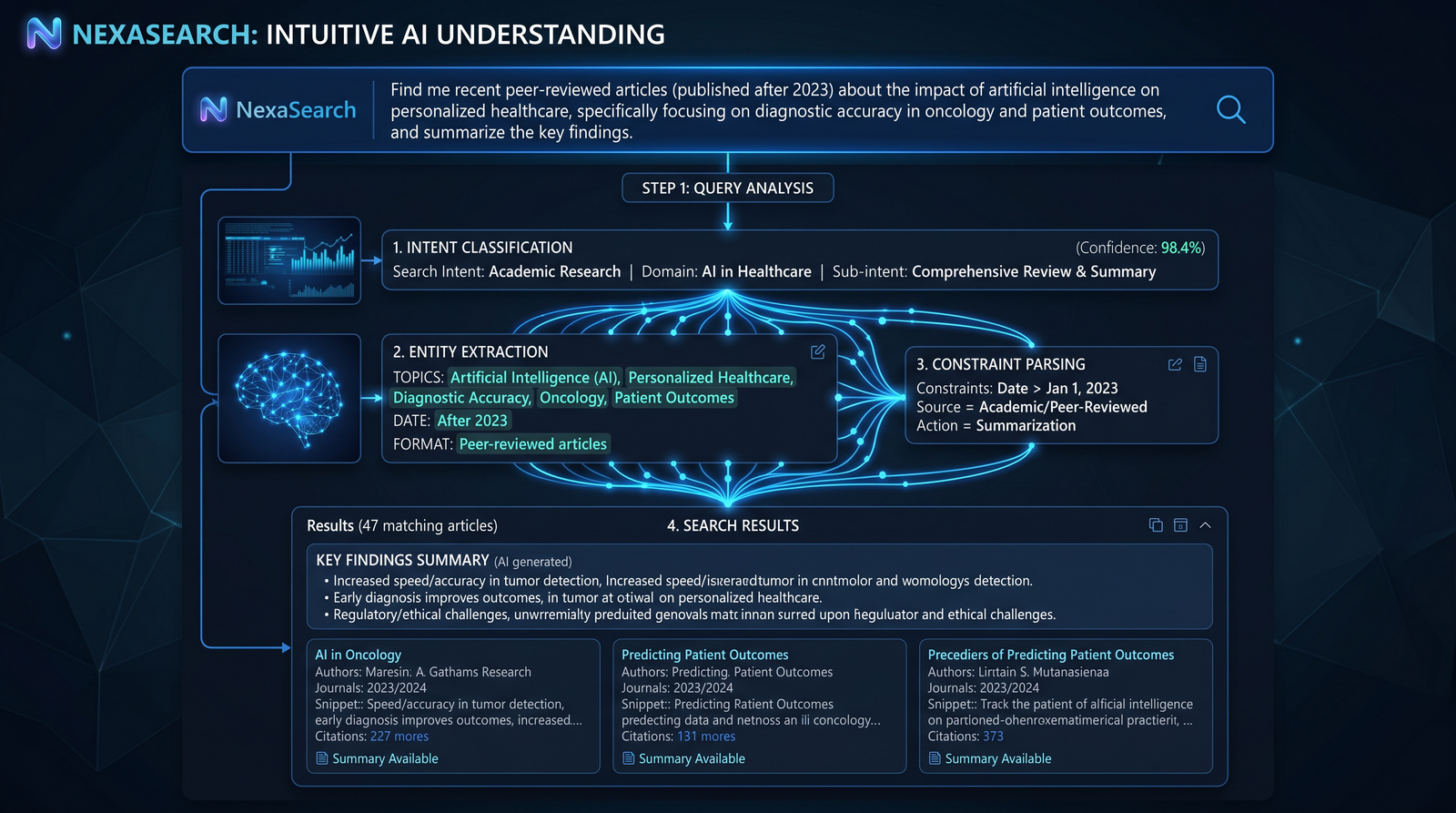
Building AI-Powered Search with GPT-5.5 Instant: From Query Understanding to Result Ranking and Personalization
Modern search systems must deliver high relevance under strict latency and cost budgets, while handling ambiguous, multi-faceted natural language. GPT-5.5 Instant enables a new class of AI-powered search by combining fast intent understanding, robust constraint handling, and structured tool outputs with traditional information retrieval. This guide describes an end-to-end architecture that layers query understanding, retrieval, ranking, and personalization, with practical Python code, design trade-offs, evaluation methodology, and cost optimization tactics.
We will cover how to leverage semantic embeddings with hybrid lexical retrieval, how to parse natural language filters into structured queries reliably, and how to add personalization without sacrificing fairness or transparency. The examples assume you operate a product or content catalog, but the patterns apply broadly to documentation, media, knowledge bases, and enterprise search.
Audience: This guide targets search engineers, platform architects, and applied ML practitioners who need to ship production-grade systems and understand the implications of model selection, index design, and online evaluation.
Why GPT-5.5 Instant for Search
GPT-5.5 Instant is optimized for fast, instruction-following interactions with improved intent understanding and constraint handling. For search, these capabilities matter in four ways:
1) Better disambiguation and reformulation: It can rewrite vague or long-winded queries into targeted forms and clarify implicit constraints (e.g., “quiet ultrabook for programming under 1200” → target category=laptops, attributes=noise_level:low, RAM:≥32GB, price:<1200).
2) Structured extraction and validation: With JSON schemas and tool use, it outputs machine-verifiable filters, facets, and sorting preferences, reducing brittle regex rules.
3) Multi-faceted reasoning: It balances hard constraints (must-have filters) and soft preferences (nice-to-haves) and can generate defensible rationale for ranking features.
4) Latency-aware reranking: It supports compact, instruction-bound reranking prompts that scale to top-k and meet sub-200 ms budgets when combined with ANN retrieval.
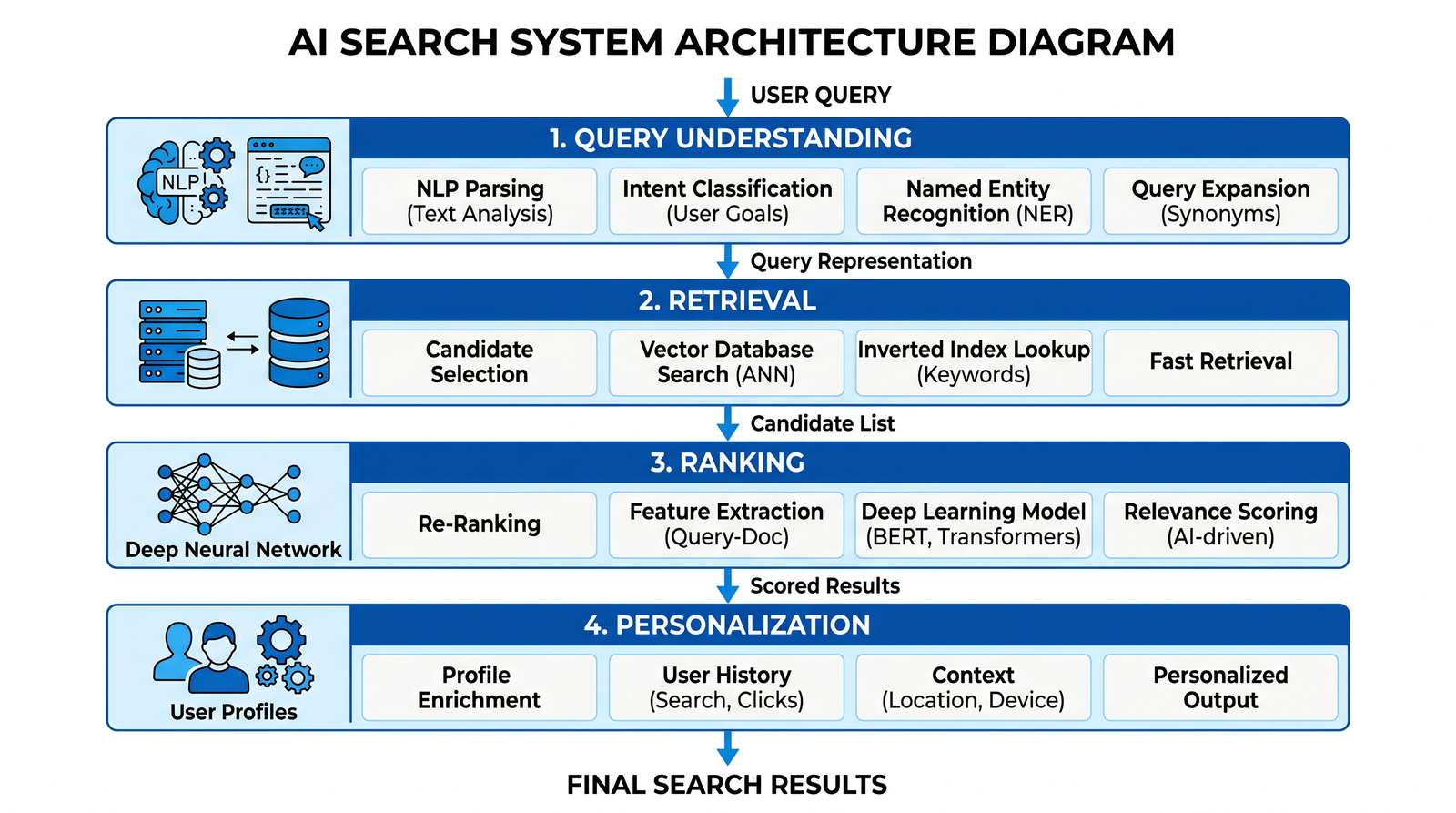
System Architecture Overview
A robust AI-powered search system is layered. Each layer has a clear contract, enabling independent iteration and evaluation:
1) Query Understanding Layer: Parse intent, entities, facets, constraints, and sorting preferences from natural language. Produce a normalized query object and a disambiguated rewrite. Identify ambiguous fields and optionally elicit clarification.
2) Retrieval Layer: Return a candidate set with high recall using hybrid retrieval (lexical + dense) and domain filters. Maintain multiple indexes (inverted, ANN, metadata) and use light heuristics to keep latency predictable.
3) Ranking Layer: Apply learned to rank features and lightweight reranking. For AI-first stacks, use a cross-encoder or an LLM reranker (GPT-5.5 Instant) to enforce constraints and optimize perceived relevance and diversity.
4) Personalization Layer: Calibrate ranking with user affinity, context, and collaborative signals while respecting privacy, fairness, and cold-start constraints.
5) Feedback and Evaluation: Track offline metrics (NDCG, Recall@k, MRR) and online telemetry (CTR, conversion, satisfaction). Use counterfactual evaluation and A/B testing to de-risk changes.
The following sections detail each layer, production patterns, and implementation code.
Data Modeling and Indexing Strategy
Strong retrieval depends on carefully modeled documents and multi-index strategy. For product and content catalogs:
Document schema: Include canonical title, normalized description, attributes (e.g., brand, category, RAM_gb, price, color), derived facets (e.g., price_bucket, popularity_percentile), and denormalized signals (e.g., review_count, rating_mean).
Lexical index: An inverted index (e.g., Elasticsearch, OpenSearch) for BM25 and facets. Configure analyzers for stemming, synonyms, and phrase queries. Maintain multi-fields for keyword and text for exact vs fuzzy matching.
Vector index: A high-recall ANN index (e.g., FAISS HNSW/IVF-PQ, Milvus, pgvector) on dense embeddings of titles + descriptions. Store vectors for both documents and facets to enable attribute-aware retrieval.
Metadata index: A columnar or key-value store for real-time filters, inventory, and pricing updates to avoid re-indexing the full vector store for small changes.
Index write path: Batch offline indexing for stable attributes; stream incremental updates (e.g., price, stock) to metadata and lexical indexes. Refresh the vector index periodically or on significant content changes.
Building a FAISS Vector Index in Python
The snippet below shows how to compute embeddings, create a FAISS index, and persist it for serving. Replace the embedding provider with your own; we illustrate using an embeddings API for clarity.
import os
import numpy as np
import faiss
from typing import List, Dict
# Example: replace with your own embedding function/provider.
# This function should return a list of float vectors of dimension D.
def embed_texts(texts: List[str]) -> np.ndarray:
# Placeholder: fetch embeddings in batches
# Return shape: (len(texts), D)
raise NotImplementedError("Integrate your embedding provider here")
def build_faiss_index(documents: List[Dict], dim: int, index_path: str):
# Prepare texts and ids
ids = np.array([doc["id"] for doc in documents]).astype("int64")
corpus = [f"{doc['title']} [SEP] {doc['description']}" for doc in documents]
# Compute embeddings (batch in production)
vectors = embed_texts(corpus).astype("float32")
# Normalize for cosine similarity (dot product on normalized vectors)
faiss.normalize_L2(vectors)
# Choose an index type (HNSW for high recall and simple ops)
index = faiss.IndexHNSWFlat(dim, 32) # M=32
index.hnsw.efConstruction = 200
index.add_with_ids(vectors, ids)
# Persist
faiss.write_index(index, index_path)
def load_faiss_index(index_path: str) -> faiss.Index:
return faiss.read_index(index_path)
Configuring a Lexical Index (Elasticsearch) for Hybrid Search
For high-precision keyword matches, phrase queries, and faceting, a lexical index complements the vector store. Configure analyzers and mappings to support multi-field queries.
from elasticsearch import Elasticsearch
es = Elasticsearch("http://localhost:9200")
mappings = {
"mappings": {
"properties": {
"id": {"type": "keyword"},
"title": {
"type": "text",
"analyzer": "standard",
"fields": {
"keyword": {"type": "keyword", "ignore_above": 256}
}
},
"description": {"type": "text"},
"brand": {"type": "keyword"},
"category": {"type": "keyword"},
"price": {"type": "float"},
"ram_gb": {"type": "integer"},
"color": {"type": "keyword"},
"rating_mean": {"type": "float"},
"review_count": {"type": "integer"},
"price_bucket": {"type": "keyword"}
}
},
"settings": {
"analysis": {
"analyzer": {
"custom_standard": {
"type": "standard",
"stopwords": "_english_"
}
}
}
}
}
es.indices.create(index="catalog", body=mappings, ignore=400)
Hybrid retrieval benefits from explicit synonyms maps (brand aliases, colloquial terms) and phrase fields for short product names. Consider adding autocomplete-specific indexes if you need instant suggestions.
Query Understanding with GPT-5.5 Instant
Query understanding transforms a raw user query into a normalized, structured form your retrieval stack can execute. GPT-5.5 Instant’s improved intent understanding and constraint handling enable high-precision parsing of multi-faceted requests with minimal rules.
Core Tasks
1) Intent classification: Identify domain intent (browse, research, transactional), sub-intent (compare, find best, troubleshoot), and category targets (e.g., laptops, headphones).
2) Constraint extraction: Parse hard filters (price caps, brand excludes, required specs), and soft preferences (style, color, “quiet”, “lightweight”). Convert these to a machine-readable schema with operators (lt, lte, gte, between, in, not_in).
3) Query rewrite: Generate a concise, unambiguous rewrite optimized for retrieval. Optionally query-expand with brand synonyms and attribute aliases.
4) Disambiguation: If ambiguous, return a short clarification question and a fallback query.
Schema and Function Calling
Use a strict JSON schema to constrain outputs. This reduces downstream parsing errors and increases determinism across languages and dialects.
QUERY_SCHEMA = {
"type": "object",
"properties": {
"normalized_query": {"type": "string"},
"category": {"type": "string"},
"must_filters": {
"type": "array",
"items": {
"type": "object",
"properties": {
"field": {"type": "string"},
"op": {"type": "string", "enum": ["eq", "lt", "lte", "gt", "gte", "between", "in", "not_in"]},
"value": {}
},
"required": ["field", "op", "value"]
}
},
"should_preferences": {
"type": "array",
"items": {"type": "string"}
},
"sort_by": {"type": "string", "enum": ["relevance", "price_asc", "price_desc", "rating_desc", "newest"]},
"clarification": {"type": "string"}
},
"required": ["normalized_query", "must_filters", "should_preferences", "sort_by"]
}
Example: Parsing a Multi-Faceted Product Query
Consider: “quiet lightweight laptop for programming under $1200, at least 32GB RAM, prefer ThinkPad or MacBook, 14-inch if possible.” We want strict filters for price and RAM, soft preferences for weight, noise, and brands, and a precise normalized query.
import json
SYSTEM_PROMPT = """You are a search query parsing agent.
Extract hard constraints as must_filters and soft preferences as should_preferences.
Return concise normalized_query suitable for retrieval.
If ambiguous, provide a short clarification question."""
USER_QUERY = "quiet lightweight laptop for programming under $1200, at least 32GB RAM, prefer ThinkPad or MacBook, 14-inch if possible"
# Pseudocode for invoking GPT-5.5 Instant with a JSON schema
def parse_query_with_gpt(query: str) -> dict:
# Replace this with your provider's structured output / function calling API.
# The important part is: pass SYSTEM_PROMPT, enforce QUERY_SCHEMA, request JSON.
raise NotImplementedError("Integrate GPT-5.5 Instant structured output here")
parsed = parse_query_with_gpt(USER_QUERY)
print(json.dumps(parsed, indent=2))
Expected output (illustrative): normalized_query: “lightweight quiet programming laptop 32GB RAM 14-inch”, category: “laptops”, must_filters: [{field: “price”, op: “lt”, value: 1200}, {field: “ram_gb”, op: “gte”, value: 32}], should_preferences: [“lightweight”, “quiet”, “brand:ThinkPad”, “brand:MacBook”, “14-inch”], sort_by: “relevance”. This structure feeds hybrid retrieval and informs reranking logic.
Constraint Handling and Validation
GPT-5.5 Instant is strong at following constraints; however, always validate in code. For numeric fields, coerce types and clamp ranges. For categorical values, map aliases to canonical values and filter invalid tokens. For safety, set maximum number of filters and maximum query length. Log parse failures for analysis and apply conservative fallbacks (e.g., ignore untrusted filters).
Semantic Retrieval with Embeddings and Hybrid Scoring
Hybrid search combines the precision of lexical retrieval with the recall and robustness of semantic embeddings. Use lexical for exact brand/product matches and filters, and semantic vectors to handle synonyms, paraphrases, and long-tail queries.
Computing Query Embeddings and ANN Search
First, embed the normalized query. Normalize vectors for cosine similarity. Then perform ANN search to retrieve top-N candidates from the vector index. Ideally, also pre-compute and store document embeddings for each facet representation to support attribute-aware filtering.
import numpy as np
import faiss
from typing import List, Dict, Tuple
def embed_query(text: str) -> np.ndarray:
# Return shape: (1, D), float32 normalized
raise NotImplementedError("Integrate your embedding provider here")
def ann_search(index: faiss.Index, qvec: np.ndarray, k: int = 200) -> Tuple[np.ndarray, np.ndarray]:
# qvec shape (1, D), returns (scores, ids)
scores, ids = index.search(qvec, k)
return scores[0], ids[0]
def hybrid_candidates(query: str, faiss_index: faiss.Index, k: int = 200) -> List[int]:
qvec = embed_query(query).astype("float32")
faiss.normalize_L2(qvec)
scores, ids = ann_search(faiss_index, qvec, k)
return ids.tolist()
Lexical Retrieval and Faceting
Issue a parallel BM25 search on title and description fields, with keyword boosts on exact title matches and brand fields. Apply must_filters directly in the query DSL to reduce candidate volume before reranking.
from elasticsearch import Elasticsearch
def build_es_query(normalized_query: str, must_filters: List[Dict], size: int = 200) -> dict:
must_clauses = [
{"multi_match": {"query": normalized_query, "fields": ["title^4", "description^1"]}}
]
for f in must_filters:
field, op, value = f["field"], f["op"], f["value"]
if op in ("eq", "in"):
if op == "eq":
must_clauses.append({"term": {field: value}})
else:
must_clauses.append({"terms": {field: value}})
elif op in ("lt", "lte", "gt", "gte"):
must_clauses.append({"range": {field: {op: value}}})
elif op == "between":
must_clauses.append({"range": {field: {"gte": value[0], "lte": value[1]}}})
return {
"query": {"bool": {"must": must_clauses}},
"size": size,
"track_total_hits": False
}
def lexical_candidates(es: Elasticsearch, normalized_query: str, must_filters: List[Dict], size: int = 200):
q = build_es_query(normalized_query, must_filters, size)
resp = es.search(index="catalog", body=q)
hits = [int(h["_source"]["id"]) for h in resp["hits"]["hits"]]
return hits
Fusion: Combining ANN and BM25 Scores
Simple rank fusion boosts stability. Common strategies include Reciprocal Rank Fusion (RRF) and z-score normalization. Calibrate weights offline to balance precision and recall.
from collections import defaultdict
def rrf_fusion(ann_ids: List[int], bm25_ids: List[int], k: int = 60, c: float = 60.0) -> List[int]:
ranks = defaultdict(lambda: 0.0)
for r, doc_id in enumerate(ann_ids[:k]):
ranks[doc_id] += 1.0 / (c + r + 1)
for r, doc_id in enumerate(bm25_ids[:k]):
ranks[doc_id] += 1.0 / (c + r + 1)
return [doc for doc, _ in sorted(ranks.items(), key=lambda x: -x[1])]
End-to-end, the retrieval layer returns a top-200 candidate pool, already filtered by hard constraints and enriched by semantic matches, ready for reranking.
Reranking with GPT-5.5 Instant and Cross-Encoders
Reranking converts a recall-oriented candidate set into a high-precision, ordered list. Options include heuristic learning-to-rank, cross-encoders (e.g., Transformer classification heads), and LLM-based reranking with GPT-5.5 Instant. Choose based on latency and cost budgets.
Cross-Encoder Reranking (Cost-Efficient Baseline)
Cross-encoders score query-document pairs directly and are strong baselines under tight budgets. They require fine-tuning but offer predictable latency.
# Example sketch: using a hypothetical cross-encoder scoring function
from typing import List, Dict
def cross_encoder_score(query: str, candidates: List[Dict]) -> List[float]:
# Returns scores aligned with candidates
raise NotImplementedError("Integrate a cross-encoder model like sentence-transformers CrossEncoder")
def rerank_with_cross_encoder(query: str, candidates: List[Dict], top_k: int = 20) -> List[Dict]:
scores = cross_encoder_score(query, candidates)
ranked = sorted(zip(candidates, scores), key=lambda x: -x[1])
return [c for c, _ in ranked[:top_k]]
LLM Reranking with Constraint Enforcement
GPT-5.5 Instant can apply nuanced reasoning about soft preferences (“quiet”, “lightweight”) and strict constraints (“RAM ≥ 32GB”). Use compact, structured prompts and ask the model to output only the final ID ordering plus a rationale per top item.
import json
from typing import List, Dict
LLM_RERANK_SYSTEM = """You are a search reranker.
Rank items by relevance to the query and enforce must-have constraints strictly.
Prefer soft preferences but never violate hard constraints.
Return JSON with fields: ranked_ids (list[int]), rationales (dict[str, str])."""
def llm_rerank(query: str, must_filters: List[Dict], should_prefs: List[str], candidates: List[Dict]) -> Dict:
# Build a compact candidate summary to fit within token limits
# Each candidate: id, title, key attributes used for constraints & prefs
summaries = []
for c in candidates:
summ = {
"id": c["id"],
"title": c.get("title", "")[:120],
"brand": c.get("brand", ""),
"price": c.get("price", None),
"ram_gb": c.get("ram_gb", None),
"weight_kg": c.get("weight_kg", None),
"noise_level": c.get("noise_level", None),
"size_inch": c.get("size_inch", None),
"rating_mean": c.get("rating_mean", None)
}
summaries.append(summ)
prompt = {
"query": query,
"must_filters": must_filters,
"should_preferences": should_prefs,
"candidates": summaries,
"output_schema": {"ranked_ids": "list[int]", "rationales": "map[id]->string"}
}
# Pseudocode: Call GPT-5.5 Instant with LLM_RERANK_SYSTEM and prompt JSON.
# Ensure temperature=0, maximum output tokens bounded, and JSON-only response.
raise NotImplementedError("Integrate GPT-5.5 Instant reranking call")
# The response should be something like:
# {"ranked_ids":[101, 205, 11, 77, ...], "rationales":{"101":"Meets RAM>=32, quiet, 14-inch", ...}}
Latency tips: Limit candidate summaries to essential fields. Keep top-K to 50–200 for the LLM and finalize with a simple scoring blend (e.g., add popularity priors) if needed. Always validate the returned IDs against the candidate set to guard against hallucinated IDs.
Mixing Rerankers
A practical pattern is tiered reranking: use a cross-encoder to prune from 200 to 60 quickly, then ask GPT-5.5 Instant to finalize top-20. This preserves nuance for final results while containing LLM costs and latency.
Natural Language Filters to Structured Queries
Users express constraints in rich, messy ways. Map these to structured, validated filters that your retrieval engine can enforce. Combine lightweight grammars for common attributes (price, rating) with GPT-5.5 Instant for long-tail and ambiguous cases.
Designing a Filter DSL
Create a compact DSL that covers your domain operators and attribute types:
price < 1200; ram_gb >= 32; brand in [“lenovo”, “apple”]; color not_in [“pink”]; size_inch between [13, 14.5]
Define canonical attribute names, allowed ranges, and enumerations. Map synonyms and units (e.g., “14-inch”, “14 in”, “14” → size_inch=14).
Hybrid Grammar + LLM Parsing
Use deterministic regex/grammar for high-precision attributes (price, RAM, storage), then pass the residual query to GPT-5.5 Instant for soft descriptors and less common attributes. Merge results with prioritization: grammar-derived filters override LLM-derived if conflicts arise, unless user intent clearly indicates otherwise.
import re
from typing import Tuple, Dict, List
PRICE_RE = re.compile(r"(?:under|<|less than)\s*\$?(\d+)", re.I)
RAM_RE = re.compile(r"(?:at least|≥|>=|minimum)\s*(\d+)\s*gb\s*ram", re.I)
def parse_with_grammar(q: str) -> Tuple[List[Dict], str]:
must_filters = []
residual = q
m = PRICE_RE.search(q)
if m:
price = float(m.group(1))
must_filters.append({"field": "price", "op": "lt", "value": price})
residual = PRICE_RE.sub("", residual)
r = RAM_RE.search(q)
if r:
ram = int(r.group(1))
must_filters.append({"field": "ram_gb", "op": "gte", "value": ram})
residual = RAM_RE.sub("", residual)
residual = " ".join(residual.split())
return must_filters, residual
def parse_filters(q: str) -> Dict:
grammar_filters, residual = parse_with_grammar(q)
# Use LLM to parse remaining filters/preferences from residual
llm_out = parse_query_with_gpt(residual) # See earlier function stub
# Merge with priority to grammar-derived hard filters
must = { (f["field"], f["op"]): f for f in llm_out["must_filters"] }
for gf in grammar_filters:
must[(gf["field"], gf["op"])] = gf
merged = list(must.values())
llm_out["must_filters"] = merged
return llm_out
Handling Multi-Faceted Queries
Multi-faceted queries include multiple constraints and preferences, sometimes across categories (“laptop bag that fits 16-inch laptop, waterproof, under $80”). The key is to preserve precision for hard constraints while allowing soft preferences to drive ranking, not filtering.
Strategies
1) Early constraint separation: Parse into must vs should and apply must to retrieval filters. Keep should for reranking signals.
2) Attribute-aware embeddings: Augment document embeddings with attribute tokens (e.g., “[RAM_32]”, “[WATERPROOF]”) to improve semantic recall for attribute-driven queries.
3) Facet bridging: When queries span related categories (e.g., laptop + bag), either treat as a two-hop search with linking attributes (size_inch) or ask GPT-5.5 Instant to choose the dominant category and carry the cross-attribute as a filter.
4) Soft label calibration: Convert should_preferences into numeric features (e.g., quiet=0/1, weight_score) during reranking for tighter control than free-text prompts.
Product Search: End-to-End Patterns
Product search adds price sensitivity, stock/inventory constraints, and merchandising policies. GPT-5.5 Instant helps to parse natural language filters and support nuanced ranking, while your business rules enforce compliance.
Category Inference and Attribute Canonicalization
Infer the dominant category and convert synonyms to canonical attributes. Maintain a dictionary of category-specific attributes and value normalization (e.g., “ThinkPad” → brand=lenovo; “MacBook” → brand=apple; “quiet” → noise_level ∈ {low, very_low}). GPT-5.5 Instant can handle aliasing but ensure you verify against a controlled vocabulary.
Inventory, Price, and Merchandising
Always apply availability filters and regional price during retrieval. For sponsored or promoted items, inject business scores only after constraints are satisfied. Keep the LLM rerank rationale separate from business rule overrides for transparency.
Example: Product Search Pipeline
from typing import Dict, List
from elasticsearch import Elasticsearch
import faiss
import numpy as np
def product_search(user_query: str,
es: Elasticsearch,
faiss_index: faiss.Index,
catalog_lookup: Dict[int, Dict],
top_ann: int = 200,
top_bm25: int = 200,
final_k: int = 20) -> Dict:
# 1) Parse query
parsed = parse_filters(user_query)
normalized = parsed["normalized_query"]
must_filters = parsed["must_filters"]
should_prefs = parsed["should_preferences"]
# 2) Retrieve candidates
ann_ids = hybrid_candidates(normalized, faiss_index, k=top_ann)
bm25_ids = lexical_candidates(es, normalized, must_filters, size=top_bm25)
fused_ids = rrf_fusion(ann_ids, bm25_ids, k=100)
# 3) Materialize candidate docs
candidates = [catalog_lookup[i] for i in fused_ids if i in catalog_lookup]
# 4) Apply business filters (availability, region)
candidates = [c for c in candidates if c.get("in_stock", True)]
# 5) Rerank (tiered)
pruned = rerank_with_cross_encoder(normalized, candidates, top_k=60)
llm_out = llm_rerank(normalized, must_filters, should_prefs, pruned)
# 6) Merge with business scoring (post-LLM)
ranked_ids = [i for i in llm_out["ranked_ids"] if any(c["id"] == i for c in pruned)]
# Example business boost: mildly boost very high ratings
final = []
for i in ranked_ids:
c = next(c for c in pruned if c["id"] == i)
c = dict(c)
c["final_score"] = c.get("popularity", 0) * 0.1 + c.get("rating_mean", 0) * 0.05
final.append(c)
# 7) Return results with rationales
rationales = llm_out.get("rationales", {})
return {"results": final[:final_k], "rationales": {str(i): rationales.get(str(i), "") for i in ranked_ids}}
Personalization Layer
Personalization improves relevance but must be balanced with diversity, fairness, and cold-start coverage. Treat it as a calibrated signal in the ranking ensemble, not a hard filter, to avoid echo chambers.
User Representation
1) Behavioral embeddings: Average embeddings of items the user engaged with, time-decayed to emphasize recent interests. Store separate vectors per intent (browse vs buy) if you have labels.
2) Profile and context: Region, language, device, price sensitivity proxies (e.g., typical purchase price), and declared preferences (brands, categories). Avoid storing raw PII; use hashed or categorical representations.
3) Collaborative signals: Similar-user cohorts, represented as centroids for privacy-preserving affinity.
Feature Blending in Reranking
Compute a personalization score per candidate and blend with semantic and LLM scores using learned weights or simple linear combination. Enforce guardrails to limit dominance (e.g., cap personalization weight at 0.3 for new sessions).
import numpy as np
from typing import Dict, List
def cosine(a: np.ndarray, b: np.ndarray) -> float:
return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b) + 1e-8))
def user_embedding_from_history(item_ids: List[int], item_vecs: Dict[int, np.ndarray], decay: float = 0.9) -> np.ndarray:
weights, vecs = [], []
for t, iid in enumerate(reversed(item_ids)):
if iid in item_vecs:
vecs.append(item_vecs[iid])
weights.append(decay ** t)
if not vecs:
return None
v = np.average(np.stack(vecs), axis=0, weights=np.array(weights))
return v / (np.linalg.norm(v) + 1e-8)
def apply_personalization(user_vec: np.ndarray, candidates: List[Dict], item_vecs: Dict[int, np.ndarray], alpha: float = 0.2):
if user_vec is None:
return candidates
rescored = []
for c in candidates:
pid = c["id"]
base = c.get("score", 0.0)
p = cosine(user_vec, item_vecs.get(pid, np.zeros_like(user_vec))) if pid in item_vecs else 0.0
c2 = dict(c)
c2["score"] = base * (1 - alpha) + p * alpha
rescored.append(c2)
return sorted(rescored, key=lambda x: -x["score"])
Fairness, Diversity, and Controls
Protect against over-narrow results by introducing intra-list diversity constraints (e.g., brand diversity, price range diversity) and by capping personalization weight for early interactions. Allow users to opt out or adjust personalization settings explicitly.
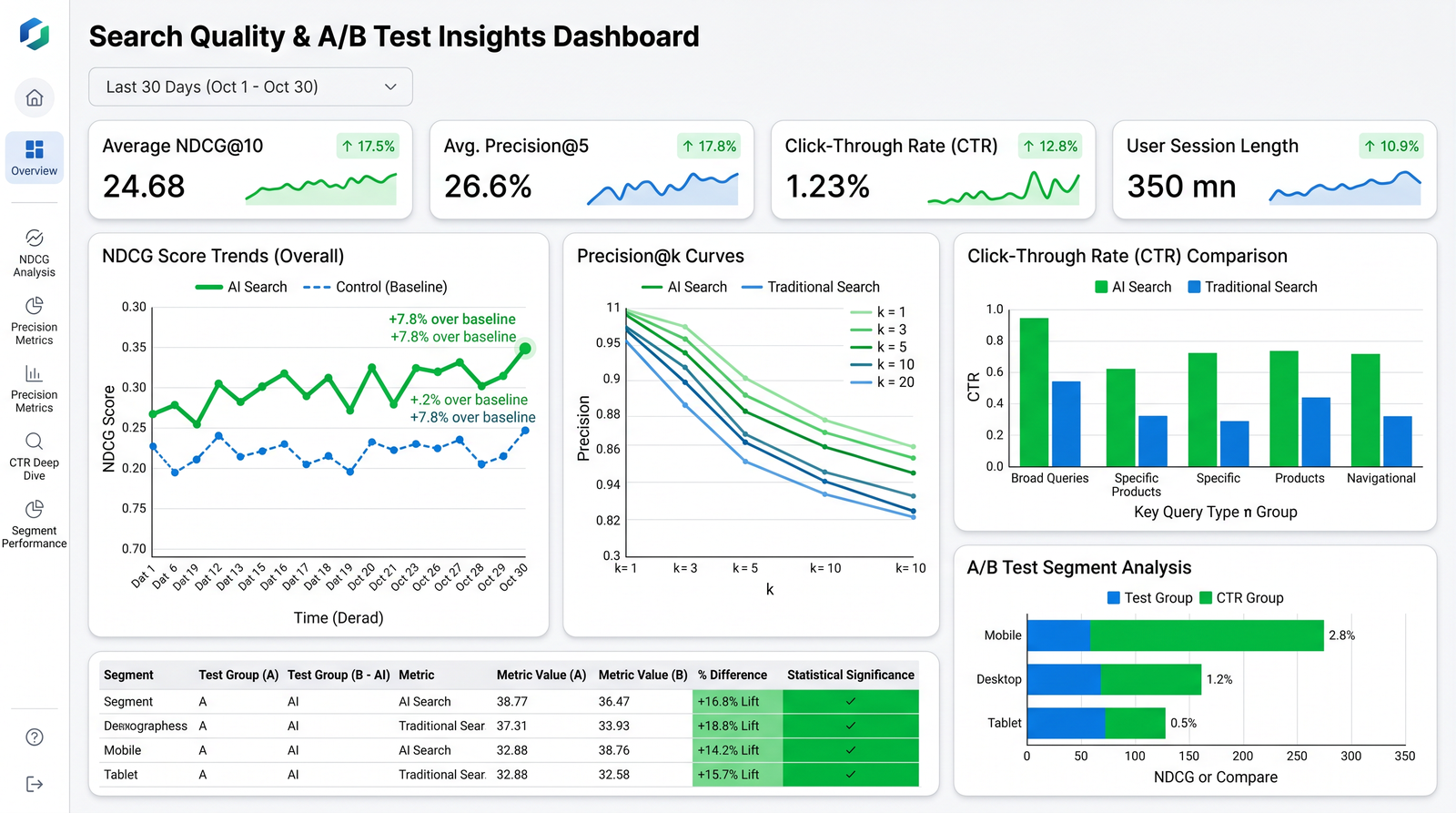
Evaluation: Offline and Online Metrics
Evaluate each layer with targeted metrics and a trustworthy labeling strategy. Combine offline evaluation with online A/B tests to validate user impact.
Offline Relevance Metrics
1) Recall@k: Fraction of relevant items found within top-k.
2) Precision@k: Fraction of returned top-k that are relevant.
3) MRR: Mean reciprocal rank of the first relevant result.
4) NDCG@k: Normalized Discounted Cumulative Gain, rewarding high ranks for highly relevant items.
5) Coverage: Percentage of queries returning any results, and any results within constraints.
Online Metrics
1) CTR@k and dwell time: Interaction signals measuring attractiveness and engagement.
2) Conversion rate and revenue per session for product search.
3) Query reformulation rate: Lower is better; indicates better first-attempt satisfaction.
4) Latency and time-to-first-byte: Directly impact abandonment.
Offline Metric Computation in Python
from typing import List, Dict
import math
def dcg(relevances: List[float]) -> float:
return sum(rel / math.log2(i + 2) for i, rel in enumerate(relevances))
def ndcg_at_k(ground_truth_ids: List[int], ranked_ids: List[int], k: int = 10) -> float:
rels = [1.0 if rid in ground_truth_ids else 0.0 for rid in ranked_ids[:k]]
ideal_rels = sorted(rels, reverse=True)
return (dcg(rels) / (dcg(ideal_rels) + 1e-9))
def mrr(ground_truth_ids: List[int], ranked_ids: List[int]) -> float:
for i, rid in enumerate(ranked_ids):
if rid in ground_truth_ids:
return 1.0 / (i + 1)
return 0.0
def recall_at_k(ground_truth_ids: List[int], ranked_ids: List[int], k: int = 10) -> float:
return len(set(ground_truth_ids).intersection(set(ranked_ids[:k]))) / (len(set(ground_truth_ids)) + 1e-9)
Labeling and Judging
Use a blend of human judgments, click-derived relevance (with position bias correction), and model-assisted synthetic labels. GPT-5.5 Instant can help generate candidate judgments quickly, but always validate with humans for ground truth on critical queries and high-impact categories.
Cost Optimization and Latency Control
Search must be fast and affordable at scale. Design for efficiency at each layer: embeddings, retrieval, reranking, and personalization. Budget tokens carefully for GPT-5.5 Instant and ensure caching wherever possible.
Token and Call Budgeting for GPT-5.5 Instant
1) Compact prompts: Use structured, minimal fields; avoid verbose descriptions. Summarize candidate attributes to the minimum needed for constraints.
2) Tiered reranking: Apply cross-encoder pruning before LLM reranking, reducing LLM top-K.
3) Response compression: Ask for ranked IDs and rationale only for top-5, not all candidates.
4) Caching: Cache parsed query objects and reranked IDs for popular queries with TTLs. Invalidate cache on major index updates.
Embedding Costs
1) Batch embeddings: Group texts to reduce request overhead.
2) Dimensionality and quantization: Consider PCA or product quantization (PQ) to reduce memory and improve ANN performance with acceptable recall trade-offs.
3) Update cadence: Re-embed only on substantial content changes; separate fast-changing metadata into side stores.
ANN Index Optimization
1) Parameter tuning: For HNSW, calibrate M and efSearch to balance recall and latency. For IVF-PQ, choose adequate nlist and nprobe.
2) Hybrid first-stage pruning: Apply cheap metadata and lexical filters to shrink the ANN candidate pool.
3) Hardware alignment: Use SIMD-friendly normalized vectors; prefer float16 if supported with negligible quality loss.
Caching and Batch Pipelines in Python
from functools import lru_cache
from typing import Tuple, List, Dict
import numpy as np
@lru_cache(maxsize=10000)
def cached_parse(query: str) -> Tuple[str, Tuple]:
# Cache the normalized query and frozen must_filters for hot queries
parsed = parse_filters(query)
normalized = parsed["normalized_query"]
must_filters = tuple((f["field"], f["op"], str(f["value"])) for f in parsed["must_filters"])
return normalized, must_filters
def batch_embed_texts(texts: List[str], batch_size: int = 64) -> np.ndarray:
all_vecs = []
for i in range(0, len(texts), batch_size):
batch = texts[i:i+batch_size]
vecs = embed_texts(batch) # vectorized call to provider
all_vecs.append(vecs)
return np.vstack(all_vecs)
Comparison: Reranking Options
| Approach | Quality | Latency | Cost | Notes |
|---|---|---|---|---|
| Heuristic LTR | Medium | Low | Low | Requires feature engineering, stable and predictable |
| Cross-Encoder | High | Medium | Low-Medium | Good baseline; fine-tuning recommended |
| GPT-5.5 Instant | Very High | Medium | Medium | Best at soft preference handling and nuanced constraints |
| Hybrid (CE prune + GPT) | Very High | Medium | Low-Medium | Balances accuracy and cost under strict budgets |
Comparison: Retrieval Strategies
| Strategy | Strengths | Weaknesses | Best Use |
|---|---|---|---|
| Lexical (BM25) | Precise terms, facets, phrase queries | Synonyms/paraphrase blind, brittle to typos | Short product names, exact brand queries |
| Dense (ANN) | Synonyms, paraphrase robustness, long-tail | Can drift semantically, needs good embeddings | Long/complex queries, attribute-driven intent |
| Hybrid Fusion | Balances precision and recall | More infra complexity | General-purpose search with diverse queries |
Robustness, Safety, and Governance
Production search must guard against adversarial queries, harmful content, and privacy risks. GPT-5.5 Instant’s structured outputs help, but implement explicit safeguards.
1) Safety filters: Block or down-rank unsafe or disallowed content categories. Apply category-level policies before LLM reranking to prevent exposure.
2) PII minimization: Never include PII in prompts. Redact or hash IDs, and avoid free-form concatenation of sensitive fields.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
3) Rate limiting and timeouts: Enforce per-user and per-IP budgets. Fail gracefully with lexical-only fallback on LLM timeouts.
4) Monitoring: Track parse errors, empty result rates, constraint violations, and drift in click distributions across facets to detect regressions.
Middle-of-Funnel Experiences: Compare, Summarize, and Explain
After presenting results, users often want summaries or comparisons. GPT-5.5 Instant can generate concise comparisons, provided it cites attributes from your structured data to avoid hallucinations. Ask it to produce bullet summaries with attribute diffs derived from the top results’ metadata only, not ungrounded text generation.
End-to-End Orchestration
Combine the layers with a latency-aware orchestrator. Execute independent steps in parallel (lexical and ANN retrieval), then synchronize for fusion and reranking. Use circuit breakers to downgrade gracefully under load.
import concurrent.futures
from typing import Dict, List
def orchestrate_search(user_query: str,
es,
faiss_index,
catalog_lookup,
user_ctx,
item_vecs) -> Dict:
normalized, must_filters = cached_parse(user_query)
# Parallel retrieval
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as ex:
f1 = ex.submit(hybrid_candidates, normalized, faiss_index, 200)
f2 = ex.submit(lexical_candidates, es, normalized, [ {"field": f[0], "op": f[1], "value": f[2]} for f in must_filters ], 200)
ann_ids = f1.result()
bm25_ids = f2.result()
fused = rrf_fusion(ann_ids, bm25_ids, k=100)
candidates = [catalog_lookup[i] for i in fused if i in catalog_lookup and catalog_lookup[i].get("in_stock", True)]
# Personalization vector
user_vec = user_embedding_from_history(user_ctx.get("history", []), item_vecs)
# Tiered reranking
pruned = rerank_with_cross_encoder(normalized, candidates, top_k=60)
if pruned:
llm_out = llm_rerank(normalized, [ {"field": f[0], "op": f[1], "value": f[2]} for f in must_filters ], [], pruned)
ranked_ids = [i for i in llm_out["ranked_ids"] if any(c["id"] == i for c in pruned)]
ranked = [next(c for c in pruned if c["id"] == i) for i in ranked_ids]
else:
ranked = candidates[:20]
# Apply personalization blending
final = apply_personalization(user_vec, ranked, item_vecs, alpha=0.2)
return {"results": final[:20]}
Case Study: Natural Language Filters in Product Search
Scenario: You operate an electronics store. Users often ask for nuanced constraints (“silent mechanical keyboard with tactile switches under $150, compact layout, backlit, prefer Keychron”). The steps:
1) Parse with grammar for price and brand; then GPT-5.5 Instant for “silent”, “tactile”, “compact”, “backlit”. Map to canonical fields: noise_level=low, switch_type=tactile, layout ∈ {75%, 65%}, backlight=true, brand in {keychron}.
2) Retrieval: Apply hard filters (price, switch_type, backlight) in ES; retrieve semantic candidates from FAISS using the normalized query “silent tactile compact mechanical keyboard backlit keychron”.
3) Fusion and reranking: Fuse candidate lists; prune with cross-encoder; finalize with GPT-5.5 Instant ensuring hard filters are respected and soft prefs shape ordering (favor compact and Keychron).
4) Personalization: If the user previously purchased low-profile keyboards, increase score for low-profile variants but cap personalization to 0.2 to preserve diversity.
5) Evaluation: Use NDCG@10 and MRR on a labeled set of 2,000 keyboard queries. Online, run a two-week A/B test with 50/50 traffic split, tracking CTR@3, add-to-cart rate, and query reformulation rate.
Advanced Topics
Attribute-Aware Embeddings
Augment training data for embedding models with attribute tokens, or concatenate key attributes to the text before embedding (“title [SEP] description [SEP] [BRAND_lenovo] [RAM_32] [WEIGHT_light]”). This can improve recall for attribute-heavy queries without over-relying on filters.
Diversification and Novelty
Introduce xQuAD-style diversification to cover multiple intents in ambiguous queries. GPT-5.5 Instant can hypothesize sub-intents (e.g., thin-and-light vs gaming laptops) and you can allocate positions proportionally in the top-10 to each sub-intent.
Clarification Questions
When ambiguity is detected (e.g., “surface” could mean Microsoft Surface or a table surface), GPT-5.5 Instant can propose a concise question and two to three suggested refinements. Show a compact UI with chips for quick selection.
Grounded Explanations
For transparency, expose limited rationales from the reranker: “Shown because it meets RAM ≥ 32GB and is rated quiet.” Ensure rationales are derived solely from item metadata to avoid hallucinations.
Quality Assurance and Regression Testing
Set up a QA suite that exercises common and edge-case queries, including multi-constraint queries, typos, and adversarial inputs. Store golden outputs for top-k and validate that new model versions or index changes match or exceed baseline quality. Track constraint-violation rate explicitly: the fraction of returned results that violate hard filters.
Automated Guardrail Checks
Implement unit checks at each layer: parser outputs JSON matching schema; retrieval respects must_filters; reranker does not reintroduce filtered items; personalization weight caps are applied. Run these checks in CI on every deploy.
Operational Monitoring
At runtime, monitor:
1) Latency per stage (parse, retrieve ANN, retrieve BM25, fusion, rerank, personalization).
2) Error and timeout rates for GPT-5.5 Instant calls; fallback activation frequency.
3) Drift: Changes in top facets, brands, and price distributions.
4) Satisfaction proxies: CTR decay, reformulation spikes, session abandonment.
5) Cost telemetry: Token usage, per-query compute, cache hit ratios.
Security and Privacy
Minimize exposure of internal details. Never include PII or secret attributes in prompts. Enforce strict input validation against prompt injection attempts. Keep model calls on server-side only, and ensure logging scrubs sensitive values. Consider differentially private aggregation for personalization signals to protect individuals.
Putting It All Together: Reference Implementation Outline
Below is a consolidated outline tying the components into a single, testable flow. Implement the provider-specific calls where indicated and integrate your infra choices (FAISS, Elasticsearch, or equivalents).
# Reference outline (fill in provider-specific calls)
# - parse_filters(): grammar + GPT-5.5 Instant
# - hybrid_candidates(): FAISS ANN on normalized query
# - lexical_candidates(): ES BM25 with must_filters
# - rrf_fusion(): merge candidate lists
# - rerank_with_cross_encoder(): prune to ~60
# - llm_rerank(): GPT-5.5 Instant final ordering
# - apply_personalization(): blend user vector
def search_entrypoint(user_query, user_ctx):
# Parse
normalized, must_filters = cached_parse(user_query)
# Retrieve
ann_ids = hybrid_candidates(normalized, faiss_index, k=200)
bm25_ids = lexical_candidates(es, normalized, [ {"field": f[0], "op": f[1], "value": f[2]} for f in must_filters ], size=200)
fused_ids = rrf_fusion(ann_ids, bm25_ids, k=100)
# Materialize
candidates = [catalog_lookup[i] for i in fused_ids if i in catalog_lookup and catalog_lookup[i].get("in_stock", True)]
# Tiered rerank
pruned = rerank_with_cross_encoder(normalized, candidates, top_k=60)
llm_out = llm_rerank(normalized, [ {"field": f[0], "op": f[1], "value": f[2]} for f in must_filters ], [], pruned)
# Personalize
user_vec = user_embedding_from_history(user_ctx.get("history", []), item_vecs)
ranked = [c for c in pruned if c["id"] in llm_out["ranked_ids"]]
final = apply_personalization(user_vec, ranked, item_vecs, alpha=0.2)
# Return top-20 with rationales
return {"results": final[:20], "rationales": llm_out.get("rationales", {})}
Practical Tips and Common Pitfalls
1) Schema drift: As your catalog evolves, keep the parsing schema in sync. Add tests for new attributes to prevent parsing regressions.
2) Token pressure: Keep candidate summaries minimal. Elide redundant attributes and truncate long descriptions during reranking.
3) Constraint leakage: Validate LLM outputs strictly. Never allow items violating hard filters to surface.
4) Recall loss: Over-filtering early can crush recall. Prefer using soft preferences in reranking instead of in retrieval filters.
5) Cold start: For new users, reduce personalization weight and increase diversity to avoid stale patterns.
6) Vendor neutrality: Abstract model providers behind interfaces so you can swap embedding or reranking providers without refactoring core logic.
Example Queries and Walkthroughs
Example 1: “Budget noise-cancelling headphones for flights under $200, prefer Sony or Bose.”
Parsing: must_filters: price < 200, category=headphones, feature:noise_cancelling=true; should: brand:sony, brand:bose, travel. Retrieval: ANN on normalized query “budget noise cancelling headphones flights”, ES with price and feature filters. Reranking: prioritize models with airline-friendly profiles and travel tags; ensure price constraint holds. Personalization: boost previously engaged brands if applicable but cap at 0.2.
Example 2: “4K monitor for coding, 27-inch, matte, good color accuracy, USB-C, under $400.”
Parsing: must_filters: price < 400, size_inch=27, resolution=4K, port=USB-C; should: matte, color accuracy. Retrieval: Hard filter in ES, ANN on normalized query. Reranking: favor matte panels and high color-accuracy scores; ensure constraints strictly enforced. Evaluate NDCG@10 on labeled monitor queries; compare with baseline reranker.
Example 3: “Quiet lightweight laptop under $1200, 32GB RAM, prefer ThinkPad or MacBook, 14-inch if possible.”
Parsing: As earlier. Retrieval: Hybrid. Reranking: Respect RAM and price; apply soft preference boosts for quiet, lightweight, brand. Personalize: if user often chooses AMD CPUs, lightly boost AMD SKUs.
Roadmap and Iteration Strategy
Phase 1: Ship a hybrid retrieval baseline with grammar-based filters, cross-encoder reranking, and offline eval. Set up logging, dashboards, and QA harness.
Phase 2: Add GPT-5.5 Instant parsing and final reranking for top-20. Introduce limited rationales. Run A/B tests to validate uplift.
Phase 3: Add personalization with calibrated blending, intra-list diversity, and controls. Expand schema to cover more attributes and categories.
Phase 4: Optimize costs: batch embeddings, quantize ANN, caching, and tiered reranking. Introduce self-serve relevance console for quick synonym and boost updates.
Glossary and Internal Link Placeholders
Use the following placeholders to connect this guide with your broader documentation set:
For a deeper exploration of related concepts, our comprehensive guide on Why GPT-5.5’s Reduced Hallucination Rate Changes Everything: From Chat Toy provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
For a deeper exploration of related concepts, our comprehensive guide on 35 ChatGPT-5.5 Prompts for Data Analysts: SQL Generation, Dashboard Creation, St provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
For a deeper exploration of related concepts, our comprehensive guide on Audited 2026 Case Study: How Claude Opus 4.7 Shifted Engineering Velocity — Prac provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
For a deeper exploration of related concepts, our comprehensive guide on The Complete GPT-5.5 and GPT-5.6 Model Selection Guide: Choosing Between Sol, Te provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
Appendix: Failure Modes and Fallbacks
1) LLM timeout or error: Fallback to cross-encoder-only reranking. Log the failure with the candidate list for replay testing.
2) No results after constraints: Surface a “No results” explanation derived from filters and offer refinement chips (e.g., raise budget, remove brand restrict). Optionally ask GPT-5.5 Instant for one clarification question.
3) Overly vague query: Ask GPT-5.5 Instant to derive likely intents and present quick filters (e.g., screen size, RAM, budget) to collect missing constraints.
4) Adversarial inputs: Sanitize inputs, limit length, and ignore unsupported filters. Maintain an allowlist of attributes and operations.
Appendix: Data and Schema Management
Attribute dictionary: Maintain a living catalog mapping canonical names, data types, valid ranges, units, and synonyms. Integrate with your ETL so attributes are consistent across indexing and serving.
Schema versioning: Embed a schema_version in prompts and in stored query objects. When upgrading, transform old objects or invalidate caches to avoid mismatch.
Internationalization: Normalize currencies and units in parsing. Localize synonyms per language and use locale-specific analyzers for lexical indexes.
Appendix: Observability Dashboards
Suggested panels: end-to-end p50/p90 latency; LLM call rate and error rate; ANN recall vs BM25 overlap; NDCG@10 trend; CTR@3; constraint violation rate; cache hit rate; cost per 1k queries; distribution of top-3 brands/categories to catch drift.
Conclusion
GPT-5.5 Instant brings fast, reliable intent parsing and constraint handling to the core of search, enabling hybrid architectures that combine the best of classical IR with LLM reasoning. By structuring outputs, validating constraints, and tiering rerankers, you can deliver state-of-the-art relevance under real-world latency and cost budgets. Layer in careful personalization, robust evaluation, and operational observability, and you have a durable foundation for AI-powered search that adapts as your catalog and users evolve.
Author: Markos Symeonides, ChatGPT AI Hub