25 ChatGPT-5.5 Prompts for DevOps Engineers: CI/CD Pipelines, Infrastructure as Code, Monitoring Dashboards, and Incident Management

25 ChatGPT-5.5 Prompts for DevOps Engineers: CI/CD Pipelines, Infrastructure as Code, Monitoring Dashboards, and Incident Management
DevOps engineers can use conversational assistants to accelerate architecture decisions, codify operational standards, and automate repetitive toil. The 25 prompts below are designed to be immediately actionable in real-world environments. They cover end-to-end CI/CD pipelines, Infrastructure as Code, observability stacks and monitoring dashboards, and incident management. Each prompt provides a clear intention, a copy-pasteable instruction for ChatGPT-5.5, and concrete code examples or CLI snippets you can adapt to your stack. For context, example stacks touch GitHub Actions, GitLab CI, Jenkins, Argo CD, Tekton, Terraform, Helm, Kustomize, Ansible, Prometheus, Grafana, Alertmanager, Loki, OpenTelemetry, and chaos testing tools. If you are just starting, you can follow the sections in order. If you are experienced, jump straight to the prompts that target your immediate goals across
For a deeper exploration of related concepts, our comprehensive guide on The Complete GPT-5.5 and GPT-5.6 Model Selection Guide: Choosing Between Sol, Te provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
,
For a deeper exploration of related concepts, our comprehensive guide on 30 ChatGPT-5.5 Prompts for Product Managers: Roadmap Planning, User Research Syn provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
,
For a deeper exploration of related concepts, our comprehensive guide on The Codex Debugging Playbook: 20 Prompts for Systematic Bug Isolation, Root Caus provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
, and
For a deeper exploration of related concepts, our comprehensive guide on How to Use OpenAI Codex for Automated Code Review: Setting Up PR Analysis, Secur provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
.
These prompts are opinionated: they prefer declarative approaches, least-privilege security, immutable infrastructure, trunk-based development, ephemeral test environments, progressive delivery, metrics-first SLOs, and documented incident workflows. You should tailor the examples to your constraints (network, compliance, build minutes, artifact storage, data gravity). Each prompt includes trade-offs, so you can choose the right abstraction level for your organization.
How to use these prompts effectively
Paste a prompt into ChatGPT-5.5 and customize square-bracket placeholders like [REPO], [SERVICE], [CLOUD], [ENV], and [SEVERITY]. If your stack differs, append a “context block” describing your tools, versions, and conventions. Ask for diffs or migration guides when modernizing legacy pipelines. Prompt chaining also helps: start broad (design), then iterate (linting, secrets, caching), then validate (policy-as-code), then finalize (merge-ready PR with tests).
General Prompt Template
-----------------------
Context:
- Repo: [REPO_URL], Branching: [TRUNK/PR-FLOW], Runners: [SELF-HOSTED/CLOUD]
- Build: [LANGUAGE/FRAMEWORK], Artifacts: [PACKAGE/Docker], Registry: [REGISTRY]
- Infra: [CLOUD/ON-PREM], Orchestration: [Kubernetes/VM/Serverless]
- Security: [SAST/DAST/SCANS], Secrets: [Vault/KMS/GH Secrets]
- Observability: [Prometheus/Grafana], Logs: [Loki/ELK], Traces: [OTel/Jaeger]
- Policies: [OPA/Conftest/Checkov], Approvals: [CODEOWNERS/CHANGE MGMT]
Task:
[Describe concrete outcome: e.g., "Design a GitHub Actions pipeline with matrix build, Docker buildx, SBOM, image signing, and Argo CD deployment with canary."]
Deliverables:
- YAML with comments
- Minimal IAM permissions
- Caching, retry, and timeout strategy
- Rollback and drift detection steps
- Security and compliance checks
- Estimated build runtime and cost guardsCapability matrix (reference)
Tool/Capability Build Test Docker SBOM Sign Scan Deploy Policy On-Prem Runner Notes
-----------------------------------------------------------------------------------------------------------
GitHub Actions Yes Yes Yes Yes Yes Yes Yes Yes Yes Huge marketplace
GitLab CI Yes Yes Yes Yes Yes Yes Yes Yes Yes Built-in registry
Jenkins Yes Yes Yes Via Via Via Yes Via Yes Plugin-powered
Tekton Yes Yes Yes Via Via Via Yes Via Yes K8s-native pipelines
Argo CD No No No No No No Yes Via Yes GitOps deploys
Spinnaker No No Yes Via Via Via Yes No Yes Multicloud deploys
Flux No No No No No No Yes Via Yes GitOps alternative
CircleCI Yes Yes Yes Via Via Via Yes Via Cloud/Hybrid Fast to start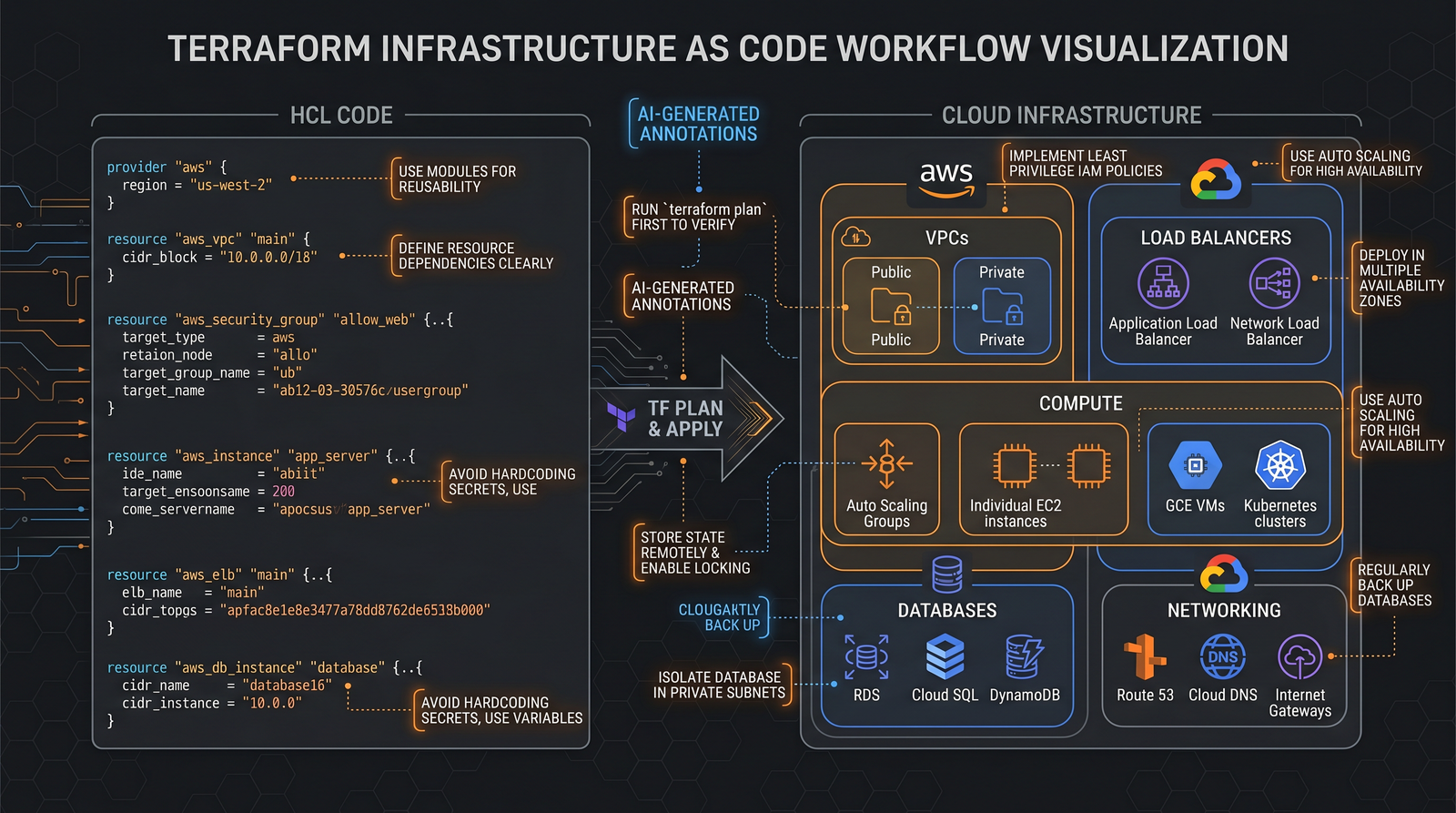
CI/CD Pipelines
Prompt 1: Design a secure, cache-efficient GitHub Actions pipeline with SBOM and image signing
Goal: Build/test a microservice, create a Docker image for multiple architectures, generate an SBOM, sign the image, scan it, push to a registry, and attach provenance. This prompt emphasizes minimal permissions, short-lived credentials, and reproducibility.
Prompt to ChatGPT-5.5:
Design a GitHub Actions workflow for [SERVICE] that:
- Runs on push and PR for dirs: [src/,Dockerfile,helm/]
- Uses build matrix for [os: ubuntu-latest], [arch: amd64,arm64]
- Sets up buildx and QEMU, caches layers, and reuses cache across jobs
- Builds Docker image with reproducible flags, tags with [sha, semver], and pushes to [REGISTRY]
- Generates SBOM (CycloneDX or SPDX) and signs image using cosign keyless (OIDC)
- Scans image and Dockerfile (Trivy or Grype)
- Uploads SBOM and scan results as artifacts
- Enforces least-privilege OIDC permissions and environment protection rules
- Includes concurrency, retry, timeout, and manual approval for main branch
- Outputs sample IAM policy (if using cloud KMS), and cost guardrails# .github/workflows/ci-build-sign.yml
name: ci-build-sign
on:
push:
branches: [ main ]
paths: [ "src/**", "Dockerfile", "helm/**" ]
pull_request:
branches: [ main ]
paths: [ "src/**", "Dockerfile", "helm/**" ]
permissions:
contents: read
id-token: write # for OIDC federated identity with cosign keyless
packages: write
concurrency:
group: build-${{ github.ref }}
cancel-in-progress: true
jobs:
build:
runs-on: ubuntu-latest
timeout-minutes: 30
strategy:
fail-fast: false
matrix:
arch: [ amd64, arm64 ]
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Set up QEMU
uses: docker/setup-qemu-action@v3
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
with:
driver-opts: |
image=moby/buildkit:rootless
- name: Log in to registry
uses: docker/login-action@v3
with:
registry: ${{ vars.REGISTRY_HOST }}
username: ${{ secrets.REGISTRY_USER }}
password: ${{ secrets.REGISTRY_TOKEN }}
- name: Compute tags
id: meta
run: |
SHA_TAG=${GITHUB_SHA::12}
echo "sha_tag=$SHA_TAG" >> $GITHUB_OUTPUT
if [[ "${GITHUB_REF##*/}" == "main" ]]; then
echo "release_tag=$(date +%Y.%m.%d).$GITHUB_RUN_NUMBER" >> $GITHUB_OUTPUT
fi
- name: Build and push
uses: docker/build-push-action@v6
with:
context: .
file: ./Dockerfile
platforms: linux/${{ matrix.arch }}
push: true
cache-from: type=gha
cache-to: type=gha,mode=max
provenance: mode=max
sbom: true
build-args: |
BUILDKIT_INLINE_CACHE=1
labels: |
org.opencontainers.image.revision=${{ github.sha }}
org.opencontainers.image.source=${{ github.repositoryUrl }}
tags: |
${{ vars.REGISTRY_HOST }}/${{ github.repository }}:${{ steps.meta.outputs.sha_tag }}-${{ matrix.arch }}
${{ vars.REGISTRY_HOST }}/${{ github.repository }}:${{ steps.meta.outputs.release_tag || 'none' }}-${{ matrix.arch }}
- name: Generate SBOM
uses: anchore/sbom-action@v0
with:
image: ${{ vars.REGISTRY_HOST }}/${{ github.repository }}:${{ steps.meta.outputs.sha_tag }}-${{ matrix.arch }}
format: spdx-json
output-file: sbom-${{ matrix.arch }}.spdx.json
- name: Install cosign
uses: sigstore/cosign-installer@v3
- name: Sign image (keyless)
env:
COSIGN_EXPERIMENTAL: "true"
run: |
IMG="${{ vars.REGISTRY_HOST }}/${{ github.repository }}:${{ steps.meta.outputs.sha_tag }}-${{ matrix.arch }}"
cosign sign --yes --identity-token $ACTIONS_ID_TOKEN_REQUEST_TOKEN $IMG
- name: Scan image
uses: aquasecurity/[email protected]
with:
image-ref: ${{ vars.REGISTRY_HOST }}/${{ github.repository }}:${{ steps.meta.outputs.sha_tag }}-${{ matrix.arch }}
format: sarif
output: trivy-${{ matrix.arch }}.sarif
ignore-unfixed: true
vuln-type: os,library
- name: Upload artifacts
uses: actions/upload-artifact@v4
with:
name: security-artifacts-${{ matrix.arch }}
path: |
sbom-${{ matrix.arch }}.spdx.json
trivy-${{ matrix.arch }}.sarifKey trade-offs: Buildx multi-arch increases time; cache warms up after 1-2 runs. Cosign keyless reduces secret sprawl but requires OIDC federation setup. SBOMs may bloat artifacts; prune retention. Gate merges on SARIF results only for critical/severe issues initially.
Prompt 2: Create a GitLab CI pipeline with dynamic environments and DAST
Goal: Spin ephemeral review apps for merge requests, run unit and integration tests, publish artifacts, run DAST against the preview URL, and tear down on merge. Enforce rules based on paths to avoid unnecessary environments.
Prompt to ChatGPT-5.5:
Draft a .gitlab-ci.yml for [SERVICE] that:
- Has stages: lint, test, build, package, review, dast, deploy, cleanup
- Creates dynamic review app per MR with unique hostname and TLS
- Uses GitLab-managed Kubernetes agent, or plain kubectl if needed
- Runs DAST against the review URL and posts findings as MR comment
- Sets resource requests/limits and TTL on environments
- Includes caching and artifact retention; uses rules:changes for monorepo
- Cleans up review apps on merge or manual action with protected runners# .gitlab-ci.yml
stages: [lint, test, build, package, review, dast, deploy, cleanup]
variables:
DOCKER_TLS_CERTDIR: ""
IMAGE: $CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA
REVIEW_DOMAIN: review.example.com
cache:
key: ${CI_COMMIT_REF_SLUG}
paths:
- .gradle/
- node_modules/
lint:
stage: lint
image: node:20-alpine
rules:
- changes: [ "web/**", "package.json" ]
script:
- npm ci
- npm run lint
test:
stage: test
image: maven:3.9-eclipse-temurin-21
rules:
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
script:
- mvn -B -ntp test
artifacts:
paths: [ "target/surefire-reports" ]
expire_in: 7 days
build:
stage: build
image: docker:27-git
services:
- docker:27-dind
rules:
- if: '$CI_COMMIT_BRANCH'
script:
- docker login -u "$CI_REGISTRY_USER" -p "$CI_REGISTRY_PASSWORD" "$CI_REGISTRY"
- docker build --pull --no-cache -t "$IMAGE" .
- docker push "$IMAGE"
artifacts:
reports:
dotenv: build.env
expire_in: 3 days
review:
stage: review
image: alpine/k8s:1.29.2
rules:
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
environment:
name: review/$CI_COMMIT_REF_SLUG
url: https://$CI_COMMIT_SHORT_SHA.$REVIEW_DOMAIN
on_stop: stop_review
auto_stop_in: 2 days
script:
- kubectl config use-context "$KUBE_CONTEXT"
- helm upgrade --install "web-$CI_COMMIT_SHORT_SHA" ./helm \
--set image.repository="$CI_REGISTRY_IMAGE" \
--set image.tag="$CI_COMMIT_SHORT_SHA" \
--set ingress.host="$CI_COMMIT_SHORT_SHA.$REVIEW_DOMAIN"
artifacts:
expire_in: 1 day
dast:
stage: dast
image: registry.gitlab.com/gitlab-org/security-products/dast:latest
needs: [ "review" ]
rules:
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
variables:
DAST_WEBSITE: https://$CI_COMMIT_SHORT_SHA.$REVIEW_DOMAIN
script:
- /analyze -t "$DAST_WEBSITE" -o dast-report.json
artifacts:
paths: [ dast-report.json ]
expire_in: 7 days
deploy:
stage: deploy
image: alpine/k8s:1.29.2
rules:
- if: '$CI_COMMIT_BRANCH == "main"'
script:
- helm upgrade --install web-prod ./helm --values ./helm/values-prod.yaml
stop_review:
stage: cleanup
image: alpine/k8s:1.29.2
variables:
GIT_STRATEGY: none
rules:
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
when: manual
environment:
name: review/$CI_COMMIT_REF_SLUG
action: stop
script:
- helm uninstall "web-$CI_COMMIT_SHORT_SHA" || truePrompt 3: Jenkinsfile with shared libraries, parallel stages, and retry/backoff
Goal: Use Jenkins declarative pipeline with shared library steps, isolated credentials, parallelization, and robust retries for flaky integration tests and artifact uploads.
Prompt to ChatGPT-5.5:
Produce a Jenkinsfile for [SERVICE] that:
- Uses a shared library @lib for common steps
- Caches dependencies, runs unit+integration tests in parallel
- Builds/pushes Docker image with buildx
- Retries flaky tasks with exponential backoff
- Splits stages with post conditions for always/cleanup
- Annotates PRs with test summaries using GitHub status// Jenkinsfile
@Library('[email protected]') _
pipeline {
agent { label 'linux-docker' }
options {
skipDefaultCheckout()
timeout(time: 45, unit: 'MINUTES')
buildDiscarder(logRotator(numToKeepStr: '50'))
ansiColor('xterm')
}
environment {
REGISTRY = credentials('registry-creds')
}
stages {
stage('Checkout') {
steps {
checkout scm
}
}
stage('Parallel Tests') {
parallel {
stage('Unit') {
steps {
sh 'make test-unit'
}
}
stage('Integration') {
steps {
retryWithBackoff(5, 2) {
sh 'make test-integration'
}
}
}
}
post {
always {
junit 'reports/**/*.xml'
}
}
}
stage('Buildx Image') {
steps {
sh '''
docker buildx create --use --name builder || true
docker buildx build --platform linux/amd64,linux/arm64 \
-t $REGISTRY_USR/myapp:${GIT_COMMIT:0:12} --push .
'''
}
}
}
post {
success { githubNotify context: 'ci', status: 'SUCCESS' }
failure { githubNotify context: 'ci', status: 'FAILURE' }
always { cleanWs() }
}
}Prompt 4: Tekton Pipeline for K8s-native builds with Kaniko and Cosign
Goal: Build container images inside Kubernetes without Docker-in-Docker using Kaniko, sign with Cosign, and push to a registry. Use PersistentVolumeClaim for caching and ServiceAccount with minimal permissions.
Prompt to ChatGPT-5.5:
Create Tekton Task and Pipeline for [SERVICE] that:
- Uses Kaniko to build/push image with layer cache PVC
- Signs with Cosign using KMS key [KMS_KEY_URI] via Workload Identity
- Outputs image digest and attestation
- Includes example PipelineRun with params (context, dockerfile, tag)
- Attaches NetworkPolicy and ResourceQuota examples# kaniko Task
apiVersion: tekton.dev/v1
kind: Task
metadata:
name: build-and-sign
spec:
params:
- name: context
- name: dockerfile
- name: image
- name: kmsKey
workspaces:
- name: shared
steps:
- name: build
image: gcr.io/kaniko-project/executor:v1.23.2
args:
- --context=$(params.context)
- --dockerfile=$(params.dockerfile)
- --destination=$(params.image)
- --cache=true
- --cache-dir=/cache
volumeMounts:
- mountPath: /cache
name: cache
- name: sign
image: ghcr.io/sigstore/cosign/cosign:v2.3.1
env:
- name: COSIGN_EXPERIMENTAL
value: "true"
script: |
#!/usr/bin/env sh
DIGEST=$(crane digest $(params.image))
cosign sign --key $(params.kmsKey) $(params.image)@${DIGEST}
volumes:
- name: cache
persistentVolumeClaim:
claimName: kaniko-cache
---
apiVersion: tekton.dev/v1
kind: Pipeline
metadata:
name: build-pipeline
spec:
params:
- name: context
- name: dockerfile
- name: image
- name: kmsKey
workspaces:
- name: shared
tasks:
- name: build
taskRef: { name: build-and-sign }
params:
- name: context
value: $(params.context)
- name: dockerfile
value: $(params.dockerfile)
- name: image
value: $(params.image)
- name: kmsKey
value: $(params.kmsKey)
workspaces:
- name: shared
workspace: shared
---
apiVersion: tekton.dev/v1
kind: PipelineRun
metadata:
name: build-pipeline-run
spec:
params:
- name: context
value: .
- name: dockerfile
value: ./Dockerfile
- name: image
value: registry.example.com/team/app:$(context.pipelineRun.uid)
- name: kmsKey
value: gcpkms://projects/p/locations/l/keyRings/r/cryptoKeys/k
workspaces:
- name: shared
volumeClaimTemplate:
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 5Gi
serviceAccountName: tekton-builderPrompt 5: Argo CD GitOps app-of-apps pattern with progressive delivery
Goal: Manage multiple services/environments using Argo CD applications and an app-of-apps. Integrate canary with Argo Rollouts, automated health checks, and policy gates.
Prompt to ChatGPT-5.5:
Generate Argo CD manifests for an app-of-apps structure:
- Root App points to [GIT_URL]/environments
- Environments: dev, staging, prod with different overlays (Kustomize)
- Each service uses Argo Rollouts for canary (20%, 50%, 100%) with metrics checks
- Include Argo CD Project RBAC, resource quotas, sync waves, and health checks
- Add policy gates (Conftest) pre-merge and Argo CD notifications on sync# Root App (app-of-apps)
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: root-environments
spec:
destination:
server: https://kubernetes.default.svc
namespace: argocd
project: platform
source:
repoURL: https://git.example.com/org/infra-configs.git
targetRevision: main
path: environments
directory:
recurse: true
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- CreateNamespace=true
- PrunePropagationPolicy=orphan
---
# Example Rollout snippet for canary
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: web
spec:
replicas: 4
strategy:
canary:
steps:
- setWeight: 20
- pause: { duration: 300 }
- setWeight: 50
- pause: { duration: 600 }
- setWeight: 100
trafficRouting:
nginx: {}
analysis:
templates:
- templateName: error-rate-check
startingStep: 1Prompt 6: Multi-tenant GitHub Actions with reusable workflows and CODEOWNERS approvals
Goal: Standardize pipelines across repositories with reusable workflow calls, enforce approvals for protected branches via CODEOWNERS, and propagate policy changes centrally.
Prompt to ChatGPT-5.5:
Provide a set of reusable GitHub Actions workflows in [org/.github] that teams can call:
- Build/test for common stacks (Node, Python, Go, Java)
- Docker image build+scan, SBOM, signing
- Reusable deploy to K8s via Helm with environment protection rules
- Enforce CODEOWNERS approval for prod deploys and tag releases
- Include examples of workflow_call inputs, secrets, and permissions# .github/workflows/reusable-build.yml
name: reusable-build
on:
workflow_call:
inputs:
language:
required: true
type: string
permissions:
contents: read
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- if: ${{ inputs.language == 'node' }}
run: npm ci && npm test
- if: ${{ inputs.language == 'python' }}
run: pip install -r requirements.txt && pytest -qPrompt 7: Matrix testing with service virtualization and contract tests
Goal: Expand test coverage without flakiness by using service virtualization (WireMock, Hoverfly) and consumer-driven contract tests (Pact). Use job matrices to validate multiple dependency versions.
Prompt to ChatGPT-5.5:
Write a CI pipeline that:
- Starts ephemeral mocks for downstream services via Docker Compose
- Runs Pact tests and publishes pacts to broker
- Uses a matrix of [LANG_VERSION] and [DEPENDENCY_VERSION]
- Fails fast on contract violations and uploads HTML reports# GitHub Actions snippet
strategy:
fail-fast: false
matrix:
lang: [ "python-3.11", "python-3.12" ]
dep: [ "redis-6", "redis-7" ]
steps:
- run: docker compose -f tests/mocks/docker-compose.yml up -d
- run: pytest -q --pact-publish
- uses: actions/upload-artifact@v4
with:
name: pact-reports
path: reports/pactPrompt 8: Supply chain checks with SLSA provenance and policy-as-code gates
Goal: Attach SLSA provenance to artifacts, verify signatures pre-deploy, and gate changes with OPA/Conftest or Kyverno policies.
Prompt to ChatGPT-5.5:
Add supply chain security to [SERVICE]:
- Build with provenance and attestations
- Verify cosign signatures in a pre-deploy job
- Add Conftest policy to block containers running as root or with :latest
- Fail builds on high/critical CVEs except in dev branches
- Provide example Rego and CLI invocation in CI# Example Rego (policy.rego)
package pipeline.policy
deny[msg] {
input.kind == "Deployment"
some c
input.spec.template.spec.containers[c].image == "latest"
msg := "latest tags are prohibited"
}
deny[msg] {
some c
input.spec.template.spec.containers[c].securityContext.runAsNonRoot == false
msg := "containers must run as non-root"
}
# Conftest invocation
conftest test k8s/deployment.yaml --policy policy/ --output tableInfrastructure as Code
Infrastructure as Code should be idempotent, modular, and boundary-aware. Prefer modules with input/output variables, version pinning, and state isolation. Use drift detection, cost estimation, and policy checks pre-apply. Cross-plane configuration, GitOps flows, and blue/green stacks reduce blast radius of changes.
Prompt 9: Terraform module layout with tests, state backends, and workspaces
Goal: Create a Terraform module for a microservice VPC, subnets, security groups, and a managed database with minimal IAM, plus tests using Terratest. Compare backend choices (S3+DynamoDB, GCS, Azure Blob). This is especially relevant if your clusters on
For a deeper exploration of related concepts, our comprehensive guide on Best ChatGPT Prompts for research provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
access managed services through VPC peering or PrivateLink.
Prompt to ChatGPT-5.5:
Scaffold a Terraform module for [CLOUD] that provisions:
- VPC, 3 private subnets across AZs, NAT gateways (optional), SGs
- Managed DB (RDS/Cloud SQL/SQL Database) with encryption and rotation
- Least-privilege IAM for app and CI, outputs connection info
- Remote state backend with locking, and workspace strategy for dev/stage/prod
- Terratest Golang tests and a Makefile to lint+format+test+plan# modules/network/main.tf (AWS example)
terraform {
required_version = ">= 1.6.0"
required_providers {
aws = { source = "hashicorp/aws", version = "~> 5.50" }
}
}
resource "aws_vpc" "this" {
cidr_block = var.cidr
enable_dns_support = true
enable_dns_hostnames = true
tags = { Name = var.name }
}
resource "aws_subnet" "private" {
for_each = { for i, az in var.azs : i => az }
vpc_id = aws_vpc.this.id
cidr_block = cidrsubnet(var.cidr, 4, each.key)
availability_zone = each.value
map_public_ip_on_launch = false
tags = { Name = "${var.name}-private-${each.value}" }
}
# Backend options (backend.tf example)
terraform {
backend "s3" {
bucket = "tf-state-prod"
key = "network/terraform.tfstate"
region = "us-east-1"
dynamodb_table = "tf-locks"
encrypt = true
}
}ASCII Table: Terraform state backend comparison
------------------------------------------------
Backend | Locking | Encryption | IAM/ACLs | Notes
---------------+---------+------------+----------+-------------------------------------
S3+DynamoDB | Yes | SSE-KMS | IAM | Widely used; versioning recommended
GCS | Yes* | CMEK | IAM | Use state-locking with GCS backends
Azure Blob | Yes | CMK | RBAC | Supports leases for locking
Consul | Yes | External | ACL | Legacy; useful on-prem
Local | No | OS-bound | FS ACL | For dev only; not for teamsPrompt 10: Terraform for EKS/GKE/AKS cluster with managed node groups and OIDC/IAM roles
Goal: Provision a secure Kubernetes cluster with least-privilege node roles, OIDC federation for service accounts, cluster autoscaler, and network policies. Output kubeconfig and baseline addons for logging/metrics. This dovetails with GitOps flows in Argo CD.
Prompt to ChatGPT-5.5:
Produce Terraform to create [CLOUD_K8S] with:
- OIDC provider and IAM roles for service accounts
- Managed node groups with taints/labels and spot/pool separation
- Network policy (CNI), cluster autoscaler IRSA, metrics-server, external-dns
- Private control plane, limited API access via VPN/Bastion
- Outputs for Argo CD bootstrap and workload identity# AWS EKS example snippet (using terraform-aws-eks module)
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 20.0"
cluster_name = var.name
cluster_version = "1.29"
cluster_endpoint_public_access = false
vpc_id = module.vpc.vpc_id
subnet_ids = module.vpc.private_subnets
enable_irsa = true
managed_node_groups = {
on_demand = {
instance_types = ["m6i.large"]
min_size = 2
max_size = 6
desired_size = 3
labels = { workload = "general" }
taints = [{ key = "dedicated", value = "system", effect = "NO_SCHEDULE" }]
}
spot = {
instance_types = ["m6i.large","m5a.large"]
capacity_type = "SPOT"
min_size = 0
max_size = 10
desired_size = 0
labels = { workload = "batch" }
}
}
}Prompt 11: Cross-account or cross-project deployer role with short-lived credentials
Goal: Enable CI to assume a deployer role in a target account/project using OIDC, granting write access only to specific resources. Avoid storing long-lived keys.
Prompt to ChatGPT-5.5:
Write IAM/IAM-like policy for [CLOUD] that:
- Trusts GitHub OIDC provider with repo and env claims
- Grants minimal deploy permissions to [RESOURCE_SET]
- Adds conditions on branch, tag, or subject for prod vs non-prod
- Provides example gh-actions OIDC usage and deny-by-default policy# AWS example trust policy
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": { "Federated": "arn:aws:iam::123:oidc-provider/token.actions.githubusercontent.com" },
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringLike": {
"token.actions.githubusercontent.com:sub": "repo:org/repo:ref:refs/heads/main"
}
}
}]
}Prompt 12: Helm chart with values schema, library charts, and security defaults
Goal: Package a secure Helm chart using a values.schema.json, library charts for reusable templates, PodSecurity, NetworkPolicy, and resource constraints.
Prompt to ChatGPT-5.5:
Author a Helm chart for [SERVICE] that:
- Enforces non-root, read-only rootfs, capabilities drop
- Defines values.schema.json for validation
- Adds HPA, PodDisruptionBudget, and NetworkPolicy
- Supports sidecars (e.g., OTel collector) and initContainers
- Includes example values for dev/stage/prod# templates/deployment.yaml (excerpt)
securityContext:
runAsNonRoot: true
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
capabilities:
drop: [ "ALL" ]
resources:
requests:
cpu: 200m
memory: 256Mi
limits:
cpu: 500m
memory: 512MiPrompt 13: Kustomize overlays with environment-specific patches
Goal: Maintain a base manifest and apply patches per environment (dev/stage/prod). Useful with Argo CD app-of-apps.
Prompt to ChatGPT-5.5:
Provide Kustomize base and overlays for [SERVICE] with:
- Base Deployment/Service/Ingress
- Overlays dev/stage/prod changing image tag, replicas, resources, and ingress host
- Strategic merge patches and JSON6902 patch examples
- Kustomization.yaml with commonLabels and build command# overlays/dev/kustomization.yaml
bases: [ "../../base" ]
namePrefix: dev-
commonLabels:
env: dev
images:
- name: registry.example.com/app
newTag: dev-1234
patchesStrategicMerge:
- patch.yamlPrompt 14: Policy-as-code with Checkov and OPA for Terraform pre-commit hooks
Goal: Prevent insecure Terraform changes before they reach CI by adding pre-commit hooks for fmt, validate, tflint, Checkov, and custom OPA policies.
Prompt to ChatGPT-5.5:
Create a .pre-commit-config.yaml that:
- Runs terraform fmt, validate, tflint with pinned versions
- Executes checkov with custom policy directory and soft-fail local dev
- Runs conftest on rendered plans (terraform show -json | jq)
- Caches plugins to speed up local runs
- Includes sample OPA policy to enforce tags and encryption# .pre-commit-config.yaml (excerpt)
repos:
- repo: https://github.com/antonbabenko/pre-commit-terraform
rev: v1.93.1
hooks:
- id: terraform_fmt
- id: terraform_validate
- id: terraform_tflint
- repo: https://github.com/bridgecrewio/checkov
rev: 3.2.248
hooks:
- id: checkov
args: [ "--directory", ".", "--soft-fail" ]
Monitoring Dashboards and Observability
Observability means measuring what matters with metrics, logs, and traces. Good dashboards highlight golden signals: latency, traffic, errors, saturation. Combine black-box checks, SLO-based alerts, and distributed tracing to locate bottlenecks. Minimize dashboard sprawl; create focused views by service and role (on-call vs platform). Instrument code with client libraries or auto-instrumentation where acceptable. For Kubernetes, layer cluster health, node saturation, and workload SLOs.
Prompt 15: Prometheus scrape config and recording rules for RED+USE
Goal: Provide Prometheus configuration to scrape services, define recording rules for RED (Rate, Errors, Duration) and USE (Utilization, Saturation, Errors), and generate lightweight queries for Grafana panels.
Prompt to ChatGPT-5.5:
Give prometheus.yml snippet that:
- Uses service discovery for Kubernetes endpoints
- Drops noisy metrics and relabels job labels for consistency
- Defines recording rules for http_request_rate, error_ratio, latency quantiles
- Adds USE metrics for nodes and pods
- Provides example Grafana queries for panels# rules/recording-rules.yml (excerpt)
groups:
- name: service-red
rules:
- record: service:http_requests:rate1m
expr: sum by (service) (rate(http_requests_total[1m]))
- record: service:http_errors:rate1m
expr: sum by (service) (rate(http_requests_total{code=~"5.."}[1m]))
- record: service:http_error_ratio:ratio1m
expr: service:http_errors:rate1m / service:http_requests:rate1m
- record: service:http_request_duration:p95
expr: histogram_quantile(0.95, sum by (le, service) (rate(http_request_duration_seconds_bucket[5m])))Prompt 16: Grafana dashboard JSON for SLOs and error budgets
Goal: Build a Grafana dashboard that shows SLI, SLO target, error budget burn over multiple windows, and request distributions. Calculations include multi-window, multi-burn-rate alerting. This helps on-call prioritize fixes per
For a deeper exploration of related concepts, our comprehensive guide on GPT-5.1 vs Cursor: The 2026 Head-to-Head Comparison provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
practices.
Prompt to ChatGPT-5.5:
Generate Grafana panels (JSON model or provisioning) for:
- SLI: availability (1 - 5xx/requests) and latency (p95)
- SLO targets per service and environment
- Error budget remaining and burn rate over 5m/1h/6h/24h
- Drill-down links to logs in Loki and traces in JaegerASCII Table: Error budget math example
--------------------------------------
SLO Target | Period | Budget (%) | Budget (req if 10M/mo)
-----------+--------+------------+------------------------
99.9% | 30d | 0.1 | 10,000
99.95% | 30d | 0.05 | 5,000
99.99% | 30d | 0.01 | 1,000
Burn Rate (BR) = (Observed Error Rate) / (Allowed Error Rate)
Alert if:
- BR >= 14 over 5m AND BR >= 7 over 1h (fast burn)
- BR >= 2 over 6h AND BR >= 1 over 24h (slow burn)Prompt 17: Loki log pipeline with structured logging and labels
Goal: Design a Loki stack with Promtail to ingest container logs, parse JSON, relabel fields to labels, and limit cardinality to control costs. Provide example LogQL queries for debugging timeouts.
Prompt to ChatGPT-5.5:
Draft Promtail and Loki configs:
- Parse JSON logs with fields level, msg, service, trace_id
- Map service and level to labels; keep msg as log line
- Drop chatty healthcheck routes with regex
- Provide LogQL queries for error_rate and request_id drilldown
- Add retention policies and compactor settings# promtail-config.yml (excerpt)
scrape_configs:
- job_name: kubernetes-pods
pipeline_stages:
- docker: {}
- json:
expressions:
level: level
msg: msg
service: service
trace_id: trace_id
- labels:
level:
service:
- drop:
source: msg
expression: ".*GET /healthz.*"Prompt 18: OpenTelemetry collector pipelines for metrics, traces, and logs
Goal: Capture metrics/traces/logs with an OTel collector deploying as sidecar or DaemonSet. Export to Prometheus, OTLP backends, and Loki. Add attributes like environment, region, and build SHA.
Prompt to ChatGPT-5.5:
Provide an otel-collector-config.yaml that:
- Receives OTLP over gRPC/HTTP
- Batches and retries, with tail-based sampling for traces
- Exports metrics to Prometheus and traces to Tempo/Jaeger
- Enriches with resource attributes: service.name, deployment.env, git.sha
- Includes k8sattributes processor for pod metadata# otel-collector-config.yaml (excerpt)
receivers:
otlp:
protocols:
grpc:
http:
processors:
batch:
k8sattributes:
attributes:
actions:
- key: deployment.env
value: prod
action: upsert
- key: git.sha
value: ${GIT_SHA}
action: insert
tail_sampling:
decision_wait: 10s
policies:
- name: high-latency
type: latency
latency: { threshold_ms: 1000 }
exporters:
prometheus:
endpoint: 0.0.0.0:8889
otlp:
endpoint: tempo:4317
service:
pipelines:
metrics:
receivers: [otlp]
processors: [batch]
exporters: [prometheus]
traces:
receivers: [otlp]
processors: [k8sattributes, attributes, tail_sampling, batch]
exporters: [otlp]Prompt 19: Alertmanager routing with severity, on-call schedules, and silences
Goal: Configure Alertmanager routes by team and severity, use templates for annotations, integrate with PagerDuty/Slack, and document silencing conventions and expiring maintenance windows.
Prompt to ChatGPT-5.5:
Write an alertmanager.yml that:
- Routes alerts by team label and severity
- Uses inhibit rules to suppress downstream noise when upstream is failing
- Adds templates for runbook_url, dashboard_url, and playbook hints
- Integrates with PagerDuty for P1/P2, Slack for P3/P4
- Includes examples of silences with matchers and expiry# alertmanager.yml (excerpt)
route:
group_by: [alertname, cluster, service]
routes:
- matchers: [ "team=payments" ]
receiver: pagerduty-payments
continue: true
- matchers: [ "severity=warning" ]
receiver: slack-ops
inhibit_rules:
- source_matchers: [ "alertname=KubeAPIDown" ]
target_matchers: [ "service=*" ]
equal: [ "cluster" ]Incident Management and Reliability
Incident management blends technical diagnosis with communication. Good runbooks, clear ownership, and crisp severity criteria reduce mean time to restore. Post-incident review focuses on system learning and addressing contributing factors, not blame. The prompts below help craft runbooks, classify incidents, calculate SLOs, and simulate failures.
Prompt 20: Incident classification, severity, and escalation policy
Goal: Define incident severity levels with objective triggers, business impact mapping, and escalation paths. Include RACI and communication templates.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Prompt to ChatGPT-5.5:
Create an incident policy for [ORG] that:
- Defines Sev-1..Sev-4 with business and technical triggers
- Maps to on-call rotations and response timelines
- Includes RACI and communication checklists (internal, customer)
- Provides markdown templates for incident declaration and status updatesASCII Table: Severity matrix (example)
--------------------------------------
Severity | Trigger (Objective) | Response Target | Channel | Example
---------+----------------------------+-----------------+----------------+----------------------------
Sev-1 | 50% error rate > 5m | Engage in 5m | PagerDuty P1 | Regional outage
Sev-2 | 5% error rate > 15m | Engage in 15m | PagerDuty P2 | Single AZ degraded
Sev-3 | Latency p95 +50% > 30m | Engage in 30m | Slack + Ticket | Cache miss spike
Sev-4 | Non-prod impact | Best effort | Ticket | Staging build failPrompt 21: Runbook template with diagnostic steps and dashboards
Goal: Provide a runbook template that ties symptoms to likely causes, metrics to view, commands to run, and rollback procedures. Link dashboards and traces.
Prompt to ChatGPT-5.5:
Write a runbook template for [SERVICE] including:
- Symptoms, probable causes, immediate actions
- Metrics (Prometheus queries), logs (Loki), traces (Tempo/Jaeger)
- Diagnostic commands (kubectl/k9s/ssh), feature-flag toggles
- Safe rollback steps and verification checks
- Post-restore follow-ups and preventive actions# Example diagnostic commands
kubectl get pods -n service -o wide
kubectl describe pod <pod> -n service
kubectl logs <pod> -n service --since=10m
kubectl rollout undo deployment/web -n service
kubectl port-forward svc/web 8080:80 -n servicePrompt 22: SLO design with multi-window burn alerts and runbook links
Goal: Define SLOs by service and environment, compute error budgets, and implement alerting with burn rate across fast and slow windows. Include runbook_url annotations for alerts.
Prompt to ChatGPT-5.5:
Produce Prometheus rules for [SERVICE] that:
- Compute availability SLI from RED metrics
- Alert on fast burn (5m/1h) and slow burn (6h/24h) with severity mapping
- Attach annotations: summary, impact, runbook_url, dashboard_url
- Export recording rules to speed dashboards# slo-rules.yml (excerpt)
groups:
- name: slo-availability
rules:
- record: service:sli_availability:ratio
expr: 1 - (service:http_errors:rate1m / service:http_requests:rate1m)
- alert: SLOFastBurn
expr: (1 - service:sli_availability:ratio) / (1 - 0.999) >= 14
for: 5m
labels:
severity: critical
annotations:
summary: "Fast-burn error budget for {{ $labels.service }}"
runbook_url: "https://runbooks.example.com/{{ $labels.service }}"
dashboard_url: "https://grafana.example.com/d/{{ $labels.service }}"Prompt 23: Chaos experiment to validate auto-scaling and retries
Goal: Inject controlled failures (pod kills, network latency, node pressure) to validate that autoscaling, circuit breakers, and retries keep SLOs in check. Ensure experiments are scoped and reversible.
Prompt to ChatGPT-5.5:
Design a chaos experiment for [SERVICE] on [CLUSTER] that:
- Adds 200ms p95 latency via tc for 10 minutes
- Kills 25% of pods randomly with PDB in place
- Verifies HPA scales within 5 minutes and error budget burn stays < 2
- Exits early if SLO breach probability > threshold
- Records results to an incident-lab wiki# Example tc latency injection (use in a controlled test namespace)
kubectl -n test exec -it deploy/web -- sh -c \
"tc qdisc add dev eth0 root netem delay 200ms 50ms distribution normal"Prompt 24: Automated incident timeline and post-incident review
Goal: Build a script or workflow that compiles an incident timeline from Alertmanager, Git logs, and Grafana annotations, then populates a PIR/retro template.
Prompt to ChatGPT-5.5:
Create a script that:
- Fetches alerts and silences for [INCIDENT_ID]
- Pulls Grafana annotations between T0 and Trestore
- Gathers commits and deploys from CI during the window
- Outputs a markdown timeline and opens a PR in [POSTMORTEM_REPO]
- Includes a checklist of action items with owners and due dates# timeline.py (pseudo)
events = []
events += fetch_alerts(incident_id)
events += fetch_grafana_annotations(t0, trestore)
events += fetch_deploys(repo, t0, trestore)
write_markdown(events)
open_pr("postmortems/INCIDENT_ID.md")Prompt 25: On-call readiness checklist and simulation drill
Goal: Verify teams are ready for on-call: dashboards linked, alerts with runbooks, access to prod, paging works, and quarterly game days with measured outcomes. Use this prompt before a rotation starts.
Prompt to ChatGPT-5.5:
Generate an on-call readiness checklist for [TEAM] that:
- Validates pager routing, contact methods, escalation dependencies
- Verifies runbooks exist for top-10 alerts with clear rollback steps
- Confirms dashboards have RED/USE and SLO panels with links
- Schedules a one-hour simulation drill with evaluated outcomes
- Produces a report card with gaps and ownersPutting it together: An end-to-end example
This end-to-end flow shows how a code push propagates to production with guardrails: A developer opens a PR that triggers unit tests and contract tests. A dynamic environment spins up for review and DAST. On merge to main, a signed, scanned image is built. Argo CD detects manifest changes and begins a canary rollout. Prometheus and Rollouts check error rate and latency; if healthy, traffic progresses to 100%. Grafana dashboards display live RED metrics and SLO burn. Alertmanager routes any regressions to the right on-call. OTel traces correlate service latencies with database spikes. If a canary fails, Rollouts aborts and reverts to the stable ReplicaSet; the GitOps repo retains audit history.
ASCII Table: Delivery path overview
-----------------------------------
Stage | System | Evidence/Artifact
----------------+-----------------+-------------------------------
PR Tests | CI | JUnit/Pact reports, SARIF
Preview Env | K8s + Helm | URL, DAST report
Build+Sign | Buildx+Cosign | Image digest, SBOM, signature
Scan | Trivy/Grype | Vulnerability SARIF
GitOps Deploy | Argo CD | Sync status, revision
Canary Check | Argo Rollouts | Analysis success/failure
Telemetry | Prom+Graf+OTel | RED metrics, traces
Alerting | Alertmanager | Pages, Slack notifications
Rollback | Rollouts/Argo | Previous RS, commit revertPerformance, cost, and reliability tips
– Use build caches and dependency caching to reduce CI time by 30–60% after warm-up.
– Prefer OIDC and workload identity; remove long-lived credentials from CI and nodes.
– Right-size runners; self-hosted runners for heavy builds, cloud runners for elasticity.
– Keep ephemeral environments under tight TTLs to avoid cost leaks; tag all resources.
– Limit metric label cardinality; precompute recording rules for dashboards.
– Make alerts actionable: few, precise, and mapped to runbooks with clear ownership.
– Treat GitOps repos as change ledgers; peer review infra and policy changes as you do app code.
Security and compliance considerations
Security-by-default reduces incident frequency and impact. Ensure container hardening (non-root, drop capabilities), image provenance (SBOM, signatures), secret hygiene (no plain-text in repos), network segmentation (namespaces, policies), and RBAC scoping. Automate policy checks with pre-commit and CI gates. For regulated environments, keep an audit trail for changes and approvals. Use drift detection weekly; reconcile with Git if you are adopting GitOps. Periodically verify backups and restore procedures. Dedicated security scan stages keep
For a deeper exploration of related concepts, our comprehensive guide on The Codex Task Decomposition Playbook: How to Break Complex Projects into Agent- provides detailed strategies and practical frameworks that complement the approaches discussed in this section.
and app dependencies in check across versions.
Common pitfalls and how to avoid them
– Overly broad IAM roles: scope to resources and use conditions on tags or paths.
– Flaky integration tests: add controlled retries, timeouts, and service virtualization.
– Pipeline sprawl: consolidate with reusable workflows and shared libraries.
– Alert noise: tune thresholds, add inhibit rules, and require runbooks for new alerts.
– Observability silos: unify with OTel; add correlations across logs, metrics, and traces.
– Cost blind spots: aggregate cost tags by team/service; alert on budget deltas.
Appendix: Additional snippets and references
Sample Makefile for polyglot repos
# Makefile
SHELL := /bin/bash
.PHONY: all lint test build image push scan sbom sign
all: lint test build
lint:
@echo "Linting..."
pre-commit run -a
test:
@echo "Running tests..."
if [ -f "pom.xml" ]; then mvn -B -ntp test; fi
if [ -f "package.json" ]; then npm test; fi
if [ -f "go.mod" ]; then go test ./...; fi
if [ -f "requirements.txt" ]; then pytest -q; fi
build:
@echo "Building..."
if [ -f "pom.xml" ]; then mvn -B -ntp package -DskipTests; fi
if [ -f "package.json" ]; then npm run build; fi
if [ -f "go.mod" ]; then go build ./...; fi
image:
docker buildx build --platform linux/amd64,linux/arm64 -t $(IMG) --push .
scan:
trivy image --severity HIGH,CRITICAL $(IMG) || true
sbom:
syft packages $(IMG) -o spdx-json > sbom.json
sign:
cosign sign --key $(KMS_KEY) $(IMG)Sample CODEOWNERS and branch protections
# CODEOWNERS
# Require at least one approver from platform for infra changes
infra/** @platform-team
helm/** @platform-team
k8s/** @platform-team
src/payments/** @payments-team
# Branch protection (describe in docs)
# - Require status checks to pass: lint, test, build, checkov
# - Require signed commits and linear history
# - Require CODEOWNERS review for protected pathsReference PromQL queries for dashboards
# RED metrics
sum by (service) (rate(http_requests_total[1m]))
sum by (service) (rate(http_requests_total{code=~"5.."}[5m]))
histogram_quantile(0.95, sum by (le, service)(rate(http_request_duration_seconds_bucket[5m])))
# USE metrics
node_cpu_seconds_total{mode!="idle"} / ignoring(mode) group_left sum by (instance)(node_cpu_seconds_total)
sum(container_memory_working_set_bytes) by (pod) / sum(kube_pod_container_resource_limits{resource="memory"}) by (pod)OPA Rego: enforce Kubernetes security baseline
package policy.k8s
deny[msg] {
input.kind == "Deployment"
some i
not input.spec.template.spec.containers[i].securityContext.runAsNonRoot
msg := "runAsNonRoot must be set"
}
deny[msg] {
input.kind == "Deployment"
some i
input.spec.template.spec.containers[i].securityContext.allowPrivilegeEscalation
msg := "allowPrivilegeEscalation must be false"
}Argo Rollouts analysis template example
apiVersion: argoproj.io/v1alpha1
kind: AnalysisTemplate
metadata:
name: error-rate-check
spec:
metrics:
- name: error-rate
interval: 1m
successCondition: result < 0.02
failureLimit: 1
provider:
prometheus:
address: http://prometheus:9090
query: sum(rate(http_requests_total{code=~"5.."}[1m])) / sum(rate(http_requests_total[1m]))Sample alerting rule for saturation
groups:
- name: k8s-capacity
rules:
- alert: NodeHighCPU
expr: 100 * (1 - avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m]))) > 85
for: 10m
labels:
severity: warning
annotations:
summary: "Node {{ $labels.instance }} CPU > 85%"
runbook_url: "https://runbooks.example.com/compute#cpu"Tekton/Argo CD RBAC cut-down example
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: deployer
rules:
- apiGroups: ["apps"]
resources: ["deployments", "rollouts"]
verbs: ["get", "list", "watch", "patch"]
- apiGroups: [""]
resources: ["configmaps", "secrets"]
verbs: ["get", "list", "watch"]Conclusion
These 25 prompts are building blocks for a resilient, secure, and high-velocity platform. Use them to standardize pipelines, codify infrastructure, expose service health, and professionalize incident response. Iterate with your teams: start with a golden path, then capture deviations as reusable modules or policies. Keep feedback loops tight using GitOps and SLOs. Over time, you will spend less time firefighting and more time improving the developer experience and feature delivery—exactly where DevOps adds the most value.