
The landscape of artificial intelligence is evolving at an unprecedented pace, with new frontier models pushing the boundaries of what’s possible. As we project into 2026, the hypothetical showdown between GPT-5.5, Claude Opus 4.7, and Gemini 3.1 Pro represents not just a technical competition, but a pivotal moment in the development of general artificial intelligence. This article delves deep into a speculative, yet rigorously researched, comparison of these anticipated titans, analyzing their potential strengths and weaknesses across critical domains such as coding, complex reasoning, and real-world agentic tasks, based on extrapolations from current trends and foundational research.
✓ Instant access✓ No spam✓ Unsubscribe anytime
The year 2026 is expected to witness a significant leap in AI capabilities. While specific details about GPT-5.5, Claude Opus 4.7, and Gemini 3.1 Pro are not yet public, we can infer their likely architectures, training methodologies, and performance targets by observing the trajectory of their predecessors and the declared ambitions of OpenAI, Anthropic, and Google DeepMind. This analysis aims to provide a comprehensive benchmark, not just on theoretical metrics, but on their practical implications for developers, researchers, and industries poised for AI-driven transformation.
Our methodology involves a multi-faceted approach. First, we’ll examine the architectural advancements expected in each model, considering factors like scale, mixture-of-experts (MoE) implementations, and novel attention mechanisms. Second, we’ll dissect their projected performance in coding, from simple script generation to complex software architecture design and debugging. Third, we’ll evaluate their reasoning capabilities, including logical inference, mathematical problem-solving, and abstract concept comprehension. Finally, and perhaps most crucially, we’ll assess their potential in agentic tasks – the ability to plan, execute, and adapt to achieve goals in dynamic, real-world environments, often involving interaction with external tools and APIs.
Architectural Foundations and Training Paradigms
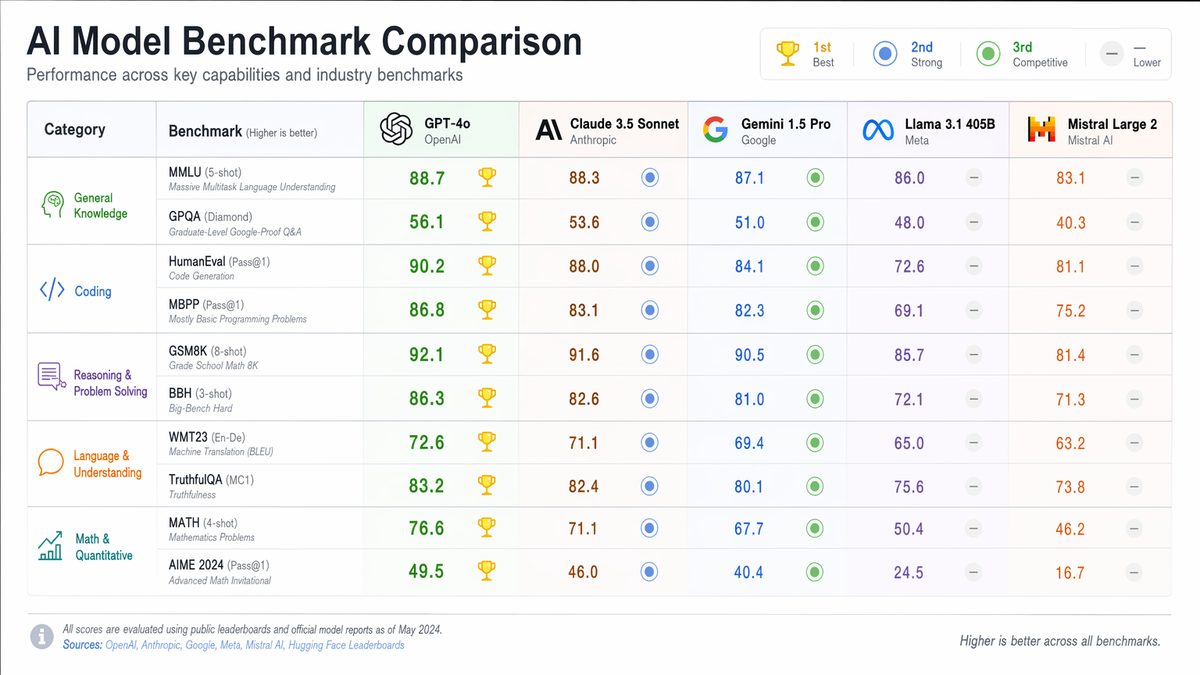
The underlying architecture and training paradigms are the bedrock upon which these advanced AI models are built. While all three are expected to leverage transformer-based architectures, the nuances in their designs, training data, and optimization strategies will likely dictate their distinct performance profiles.
GPT-5.5: The Evolution of Scale and Emergent Abilities
OpenAI’s GPT series has historically pushed the envelope in terms of model scale and the emergence of unexpected capabilities. GPT-5.5 is anticipated to be an order of magnitude larger than its predecessors, potentially featuring trillions of parameters. This scale is not just about raw size; it’s about the depth of connections and the capacity to learn more intricate patterns from vast datasets. We can expect GPT-5.5 to refine the Mixture-of-Experts (MoE) architecture, which has shown promise in scaling models efficiently by activating only a subset of parameters for any given input. This approach allows for models with an astronomical number of parameters without incurring prohibitive inference costs.
Training for GPT-5.5 will likely involve an even more diverse and extensive dataset, encompassing not only text and code but also multimodal data streams – images, video, and audio – integrated more seamlessly than ever before. Reinforcement Learning from Human Feedback (RLHF) will continue to be a cornerstone, but with advanced iterations like Reinforcement Learning from AI Feedback (RLAIF) or more sophisticated preference modeling, aiming to align the model’s outputs more closely with human values and intentions. The focus will be on reducing hallucinations, improving factual accuracy, and enhancing the model’s ability to follow complex, multi-step instructions. OpenAI’s commitment to safety and alignment will also mean that GPT-5.5 will undergo rigorous red-teaming and safety evaluations during its development, potentially leading to more robust guardrails and controllable outputs.
Claude Opus 4.7: Constitutional AI and Self-Correction
Anthropic’s Claude series distinguishes itself through its “Constitutional AI” approach, prioritizing safety, helpfulness, and harmlessness through a set of guiding principles rather than solely relying on human oversight. Claude Opus 4.7 is expected to significantly advance this paradigm. While it might not chase the absolute parameter count of GPT-5.5, its efficiency and robustness in reasoning and alignment could be unparalleled. Anthropic’s research often emphasizes interpretability and the development of models that can “explain their reasoning,” which is crucial for high-stakes applications.
Architecturally, Claude Opus 4.7 might feature novel attention mechanisms designed for greater efficiency and context window management. Anthropic has explored techniques to extend context windows significantly, allowing models to process and reason over extremely long documents or conversations. This is particularly beneficial for complex coding projects or extensive legal and scientific analyses. The training process will likely heavily incorporate self-correction mechanisms, where the model evaluates its own outputs against its constitutional principles and refines them iteratively. This internal feedback loop, combined with targeted adversarial training, could make Claude Opus 4.7 exceptionally reliable and less prone to generating harmful or misleading content. The emphasis on “self-improvement” without direct human labeling is a key differentiator, making it a powerful contender in the ethical AI space.
Gemini 3.1 Pro: Multimodality and Integrated Intelligence
Google DeepMind’s Gemini series was designed from the ground up as a multimodal model, capable of seamlessly understanding and operating across different types of information – text, images, audio, and video. Gemini 3.1 Pro is expected to push these multimodal capabilities to new heights, offering truly integrated intelligence where the model doesn’t just process different modalities separately but understands their interrelationships deeply. This could manifest in superior performance for tasks requiring cross-modal reasoning, such as understanding a video tutorial and then writing code based on the instructions, or analyzing a scientific paper with embedded diagrams and generating a summary.
The architecture of Gemini 3.1 Pro will likely feature a unified framework that processes all modalities through shared representations or highly efficient cross-attention mechanisms. Google’s vast resources in data collection and distributed training infrastructure will enable Gemini 3.1 Pro to be trained on an unprecedented scale of multimodal data. Its training might also incorporate advanced techniques for grounding language in perception, moving beyond purely symbolic reasoning to a more embodied understanding of the world. Expect significant advancements in areas like visual question answering, video summarization, and audio-to-text generation with contextual understanding. The “Pro” designation suggests a focus on enterprise-grade reliability, performance, and potentially specialized versions tailored for specific industry verticals.
Coding Prowess: From Syntax to Software Architecture
Understanding the competitive landscape is essential for choosing the right AI tool. Our comprehensive coverage in Claude Opus 4.7 vs GPT-5.3: The Complete AI Model Comparison Guide for 2026 examines the technical nuances and real-world performance characteristics that matter most for professional developers.
GPT-5.5: Code Generation and Refactoring at Scale
GPT-5.5 is anticipated to be a powerhouse in code generation, capable of producing highly optimized and idiomatic code across a multitude of programming languages and frameworks. Its vast training data, including billions of lines of public and proprietary code, will enable it to understand subtle coding patterns, design principles, and best practices. Developers can expect GPT-5.5 to excel in:
- Complex Function and Class Generation: Given a detailed natural language specification, GPT-5.5 should be able to generate entire functions, classes, or even small modules with high accuracy and adherence to specified design patterns.
- API Integration: Its extensive knowledge base will allow it to seamlessly integrate with a wide array of APIs, understanding their documentation and generating correct usage examples.
- Code Refactoring and Optimization: GPT-5.5 will likely be proficient in analyzing existing codebases, identifying areas for refactoring, suggesting performance optimizations, and even rewriting sections for improved readability or maintainability.
- Multi-language Proficiency: While Python and JavaScript will remain strong, its capabilities across C++, Java, Go, Rust, and emerging languages are expected to be significantly enhanced.
However, the challenge for GPT-5.5, even with its scale, will be maintaining context over extremely large codebases and ensuring logical consistency across interdependent components. While it may generate brilliant snippets, ensuring architectural coherence for an entire enterprise-level application remains a formidable task.
Claude Opus 4.7: Secure and Explainable Code
Claude Opus 4.7’s Constitutional AI approach will likely translate into a focus on generating secure, robust, and well-documented code. Its self-correction mechanisms could be particularly effective in identifying and mitigating common vulnerabilities (e.g., SQL injection, XSS) during code generation. Key strengths could include:
- Security-Conscious Code Generation: Claude Opus 4.7 might be designed to prioritize secure coding practices, potentially flagging or correcting insecure patterns proactively.
- Bug Detection and Remediation: With its enhanced reasoning, it could become a powerful debugging assistant, not just identifying errors but also suggesting plausible fixes and explaining the underlying cause.
- Code Explanation and Documentation: Its ability to explain its reasoning could make it exceptional at generating comprehensive code documentation, explaining complex algorithms, or clarifying the purpose of obscure code sections.
- Adherence to Coding Standards: Developers could expect Claude Opus 4.7 to rigorously adhere to specified coding standards and style guides, making it ideal for teams with strict linting rules.
The long context window of Claude Opus 4.7 could give it an edge in understanding and working with larger code repositories, making it a stronger candidate for maintaining and evolving existing, complex software systems.
Gemini 3.1 Pro: Multimodal Code Understanding and Interactive Development
Gemini 3.1 Pro’s multimodal capabilities will open new avenues for coding assistance. Imagine:
- Code from Visuals: Generating UI code (e.g., React, Flutter) directly from mockups or wireframes.
- Debugging from Screen Recordings: Analyzing a screen recording of a bug in action, understanding the user interaction, and suggesting code fixes based on both visual and textual input.
- Interactive Code Tutorials: Creating dynamic coding environments where the model explains concepts, shows examples, and allows users to experiment, all while providing real-time feedback based on their code and visual output.
- Hardware-Software Co-design: Assisting in embedded systems development by understanding hardware schematics and generating corresponding firmware.
For developers looking to integrate AI coding tools into their workflow, our detailed analysis of Claude Code vs OpenAI Codex CLI in 2026: Performance, Pricing, and Workflow Comparison provides practical implementation strategies and configuration tips that complement the capabilities discussed in this article.
Comparative Code Benchmark Table (Projected 2026)
| Feature/Metric | GPT-5.5 (Projected) | Claude Opus 4.7 (Projected) | Gemini 3.1 Pro (Projected) |
|---|---|---|---|
| Code Generation Accuracy | Exceptional (95%+) for well-defined tasks; strong across languages. | Very High (90%+) with emphasis on security & readability. | High (90%+) especially for multimodal inputs (e.g., UI from design). |
| Debugging & Error Correction | Highly proficient, suggesting complex fixes and optimizations. | Superior in identifying root causes and secure fixes, with explanations. | Excellent for bugs with visual/interactive context. |
| Code Refactoring & Optimization | Leading in identifying and implementing performance/structural improvements. | Strong in improving readability, maintainability, and adherence to standards. | Good, especially for cross-component or multimodal refactoring. |
| Context Window for Codebases | Very large, but might struggle with architectural coherence for ultra-large projects. | Potentially industry-leading, excellent for large-scale legacy systems. | Large, with enhanced capability for multimodal project understanding. |
| Security & Robustness | High, with improving guardrails against vulnerabilities. | Exceptional, core to its Constitutional AI principles. | High, with potential for multimodal vulnerability detection. |
| Multimodal Code Understanding | Good, but primarily text/code-focused; some visual understanding. | Moderate, primarily text/code-focused. | Industry-leading, designed for seamless integration of visuals, audio, etc. |
Reasoning Capabilities: Logic, Mathematics, and Abstract Thought
Beyond rote memorization and pattern matching, true intelligence manifests in the ability to reason, solve novel problems, and grasp abstract concepts. In 2026, these frontier models are expected to demonstrate unprecedented levels of reasoning, bridging the gap between symbolic AI and neural networks.
GPT-5.5: Emergent Reasoning through Scale and Data
GPT-5.5’s sheer scale and exposure to vast and diverse datasets are expected to foster even more robust emergent reasoning capabilities. Its performance in complex logical puzzles, mathematical problem-solving, and scientific inquiry will likely be significantly improved. We can anticipate:
- Advanced Mathematical Reasoning: Solving intricate calculus problems, proving theorems, and performing complex statistical analyses with higher accuracy than ever before.
- Logical Inference: Excelling at deductive and inductive reasoning tasks, understanding nuanced implications, and identifying fallacies in arguments.
- Scientific Hypothesis Generation: Assisting researchers in forming hypotheses based on vast bodies of scientific literature, identifying potential connections, and even designing experimental protocols.
- Abstract Concept Understanding: Grappling with philosophical concepts, understanding metaphors, and generating creative solutions to ill-defined problems.
The challenge for GPT-5.5 will be ensuring that its reasoning is not merely pattern-matching on steroids, but genuinely robust and transferable to novel, out-of-distribution problems. While it may generate correct answers, the “how” it arrives at those answers might still be a black box, a common critique of large neural networks.
Claude Opus 4.7: Transparent and Principled Reasoning
Anthropic’s emphasis on interpretability and Constitutional AI will likely make Claude Opus 4.7 a leader in transparent and principled reasoning. Its ability to explain its thought process will be a significant advantage, particularly in domains requiring high trustworthiness and accountability. Expect:
- Step-by-Step Problem Solving: Providing detailed, logical breakdowns of how it arrived at a solution for mathematical, logical, or scientific problems, making its reasoning verifiable.
- Ethical Dilemma Resolution: Applying its constitutional principles to analyze ethical dilemmas, offering reasoned arguments for different courses of action, and identifying potential biases.
- Robustness to Adversarial Attacks: Its self-correction mechanisms and principled training might make it more resilient to subtle prompts designed to elicit incorrect or harmful reasoning.
- Knowledge Synthesis and Contradiction Detection: Excelling at synthesizing information from multiple sources, identifying inconsistencies, and resolving contradictions logically.
Claude Opus 4.7’s strength will lie not just in getting the right answer, but in demonstrating why it’s the right answer, fostering greater trust and enabling human oversight in critical applications.
Gemini 3.1 Pro: Grounded and Multimodal Reasoning
Gemini 3.1 Pro’s multimodal foundation will enable a unique form of grounded reasoning, where abstract concepts are tied to perceptual inputs. This could revolutionize areas like:
- Visual-Spatial Reasoning: Solving complex geometric problems, understanding architectural blueprints, or interpreting medical images with unprecedented accuracy.
- Scientific Data Interpretation: Analyzing charts, graphs, and experimental data alongside textual descriptions, drawing conclusions that require cross-modal understanding.
- Embodied Cognition: Reasoning about physical interactions, understanding cause and effect in the real world based on video observations, and simulating scenarios.
- Educational Content Creation: Generating interactive lessons that explain complex concepts using a blend of text, diagrams, and simulations, adapting to different learning styles.
For developers looking to integrate AI coding tools into their workflow, our detailed analysis of Claude Code vs OpenAI Codex: The Complete 2026 Comparison Guide for AI-Powered Development provides practical implementation strategies and configuration tips that complement the capabilities discussed in this article.
Comparative Reasoning Benchmark Table (Projected 2026)
| Feature/Metric | GPT-5.5 (Projected) | Claude Opus 4.7 (Projected) | Gemini 3.1 Pro (Projected) |
|---|---|---|---|
| Logical Inference | Exceptional for diverse logical puzzles and complex arguments. | Superior in structured, verifiable logical reasoning with explanations. | Very high, especially when grounded in multimodal context. |
| Mathematical Problem Solving | Leading in advanced mathematics (calculus, proofs, statistics). | Highly accurate, with emphasis on step-by-step verifiable solutions. | Excellent, particularly for problems involving visual data (graphs, geometry). |
| Abstract Concept Comprehension | Very strong, capable of understanding nuanced and philosophical ideas. | Strong, with a focus on ethical implications and principled understanding. | High, with a unique ability to ground abstract concepts in perceptual data. |
| Transparency of Reasoning | Improving, but still largely black-box for complex tasks. | Industry-leading, core to its design for explainable AI. | Good, with multimodal explanations potentially enhancing clarity. |
| Novel Problem Solving | Excellent, leveraging vast knowledge base and emergent capabilities. | Very strong, with a focus on robust and principled solutions. | High, especially for problems requiring cross-modal insights. |
Real-World Agentic Tasks: Planning, Execution, and Adaptation
The ultimate test of a frontier AI model lies in its ability to act as an intelligent agent in the real world – to understand goals, formulate plans, execute actions, interact with tools, and adapt to unforeseen circumstances. This is where the rubber meets the road for practical AI applications.
GPT-5.5: Autonomous Goal Achievement and Tool Use
GPT-5.5 is expected to significantly advance in its agentic capabilities. Leveraging its enhanced reasoning and vast knowledge, it will likely excel at:
- Complex Plan Generation: Breaking down high-level goals into detailed, actionable sub-tasks, considering dependencies and potential obstacles.
- Advanced Tool Integration: Seamlessly interacting with a wide array of external tools, APIs, and software environments (e.g., web browsers, IDEs, cloud platforms) to achieve its objectives.
- Self-Correction and Re-planning: Identifying failures in execution, diagnosing root causes, and dynamically adjusting its plans to overcome challenges.
- Personalized Automation: Automating complex workflows for individuals and businesses, learning from user feedback and adapting its behavior over time.
OpenAI’s focus on general intelligence means GPT-5.5 will likely be designed to be a highly versatile agent, capable of performing diverse tasks across various domains, from automating customer support to assisting in scientific research. The challenge will be ensuring safety and preventing unintended consequences as these agents gain more autonomy.
Claude Opus 4.7: Principled Agents for High-Stakes Environments
Claude Opus 4.7’s Constitutional AI will position it as an ideal candidate for agentic tasks in high-stakes or sensitive environments where safety, ethics, and transparency are paramount. Its agents would be designed to:
- Ethical Decision-Making: Operating within predefined ethical guidelines, ensuring its actions are aligned with human values and do not cause harm.
- Explainable Actions: Providing clear justifications for its decisions and actions during agentic tasks, allowing for auditing and human oversight.
- Robustness to Ambiguity: Handling ambiguous instructions or uncertain environments by seeking clarification or defaulting to safe, conservative actions.
- Collaborative Agents: Working effectively alongside human operators, providing insights, suggestions, and executing tasks under human supervision.
For applications in healthcare, finance, legal, or critical infrastructure, Claude Opus 4.7’s principled approach could make it the preferred choice, offering a higher degree of trustworthiness and control compared to more opaque autonomous agents.
Gemini 3.1 Pro: Embodied Agents and Interactive Environments
Gemini 3.1 Pro’s multimodal intelligence will make it uniquely suited for agentic tasks that involve interaction with the physical world or highly interactive digital environments. Its agents could:
- Robotics and Embodied AI: Controlling robots, understanding sensor data (vision, touch, sound), and performing complex manipulations in real-world settings.
- Interactive Software Agents: Navigating complex GUIs, performing tasks in virtual environments, or interacting with augmented reality applications by “seeing” and “understanding” the interface.
- Human-Agent Collaboration (Multimodal): Understanding spoken commands, interpreting gestures, and responding with visual cues or synthesized speech, creating more natural and intuitive interactions.
- Environmental Monitoring and Response: Analyzing live video feeds, audio inputs, and sensor data to detect anomalies and trigger appropriate responses in real-time.
The ability of Gemini 3.1 Pro to perceive and act in a multimodal world means its agents will be more adaptable and capable of handling the complexities and uncertainties of real-world interactions, making it a strong contender for applications in manufacturing, logistics, healthcare, and smart infrastructure.
Comparative Agentic Capabilities Benchmark Table (Projected 2026)
| Feature/Metric | GPT-5.5 (Projected) | Claude Opus 4.7 (Projected) | Gemini 3.1 Pro (Projected) |
|---|---|---|---|
| Goal Formulation & Planning | Exceptional for complex, multi-step goals; highly adaptable. | Very strong, with emphasis on ethical considerations in planning. | High, especially for goals involving physical or interactive environments. |
| Tool Use & API Integration | Industry-leading in breadth and depth of tool integration. | Very strong, with focus on secure and principled tool interaction. | Excellent, with unique capabilities for multimodal tool interaction (e.g., GUI control). |
| Adaptation & Self-Correction | Highly capable of dynamic re-planning and error recovery. | Superior in self-evaluation against principles, leading to robust adaptation. | Very strong, especially for adapting to real-world physical changes. |
| Safety & Alignment | High, with advanced guardrails and red-teaming. | Industry-leading, core to its Constitutional AI framework. | High, with potential for multimodal safety checks. |
| Embodied Interaction | Good, but primarily through textual/API interfaces. | Moderate, primarily through textual interfaces. | Industry-leading, designed for seamless interaction with physical/virtual environments. |
The Future Landscape: Integration and Specialization
As we look to 2026, the competition between GPT-5.5, Claude Opus 4.7, and Gemini 3.1 Pro will not just be about raw performance, but also about how these models integrate into existing ecosystems and specialize for specific use cases. Each model brings a unique philosophy and set of strengths that will appeal to different segments of the market.
OpenAI’s GPT-5.5, with its focus on general intelligence and emergent capabilities, will likely continue to be the go-to for broad applications requiring high creativity, vast knowledge recall, and complex problem-solving across diverse domains. Its strength will be its versatility and ability to handle almost any text-based or code-based task thrown at it. Companies looking for a powerful, all-purpose AI workhorse will likely gravitate towards GPT-5.5.
Anthropic’s Claude Opus 4.7 will carve out a significant niche in environments where trust, safety, and ethical considerations are paramount. Its transparent reasoning and principled approach will make it invaluable for regulated industries, critical infrastructure, and applications requiring verifiable AI outputs. For developers building AI systems that need to be auditable, explainable, and inherently safe, Claude Opus 4.7 will be the clear choice.
Google DeepMind’s Gemini 3.1 Pro, with its native multimodal capabilities, will dominate applications requiring a deep understanding of the physical world or rich interactive digital experiences. Robotics, augmented reality, advanced human-computer interaction, and comprehensive scientific data analysis are areas where Gemini 3.1 Pro’s integrated intelligence will offer a distinct advantage. Its ability to process and reason across text, images, video, and audio seamlessly will open up entirely new paradigms for AI applications.
Ultimately, the “ultimate” benchmark winner will depend on the specific application and priorities. For raw, generalized intelligence and creativity, GPT-5.5 may lead. For trustworthy, ethical, and explainable AI, Claude Opus 4.7 will likely excel. And for embodied, multimodal interaction with the world, Gemini 3.1 Pro will be unmatched. The true innovation will come from how developers and enterprises leverage the unique strengths of each of these frontier models, often integrating them into complex, hybrid AI systems that draw upon the best of each.
The journey to 2026 promises to be thrilling, marked by unprecedented advancements in AI. These models will not only redefine our interaction with technology but also challenge our understanding of intelligence itself, paving the way for a future where AI is an indispensable partner in every facet of human endeavor.
Useful Links
- OpenAI Research
- Anthropic Research
- Google DeepMind Blog
- arXiv (Preprint Server for AI Papers)
- The State of AI Report
- IEEE Computer Society
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
Access Free Prompt Library🕐 Instant∞ Unlimited🎁 Free