Advanced Prompting Techniques for GPT-5.5 and Claude: The 2026 Framework
Advanced Prompting Techniques for GPT-5.5 and Claude: The 2026 Framework
Introduction
The rapid evolution of large language models (LLMs) has fundamentally transformed the landscape of artificial intelligence across multiple domains. As we step into 2026, two of the most sophisticated and widely adopted AI models are GPT-5.5 and Claude. These models represent monumental leaps in natural language understanding, contextual reasoning, and the ability to generate coherent, nuanced, and contextually appropriate responses that rival human-level performance.
GPT-5.5, developed as a successor to previous GPT iterations, incorporates groundbreaking architectural innovations that enhance its reasoning capabilities and context retention. Claude, on the other hand, has carved a niche through its emphasis on interpretability, safety, and multimodal integration, making it a preferred choice for mission-critical applications requiring ethical AI use and transparency.
While foundational prompting techniques served well in the early days of AI language models, the complexity and sophistication of GPT-5.5 and Claude demand more advanced, structured, and nuanced prompting strategies. Basic prompts no longer suffice to unlock the full potential of these models, especially for tasks requiring multi-step reasoning, context management, and dynamic adaptation.
This comprehensive article aims to deep dive into the advanced prompting techniques specifically tailored for GPT-5.5 and Claude in 2026. Readers will gain mastery over methodologies such as Chain-of-Thought (CoT) prompting, the innovative R-T-C-F (Retrieve, Think, Compose, Finalize) framework, Few-Shot prompting, and advanced contextual reasoning approaches. This knowledge is essential for developers, AI researchers, and enterprise users seeking to maximize the efficiency, accuracy, and safety of their AI-driven workflows.
By the end of this article, you will be equipped with detailed, practical guidance and theoretical insights to elevate your prompt engineering skills, ensuring you harness the full capabilities of GPT-5.5 and Claude in real-world applications.
1. Understanding the Foundations of GPT-5.5 and Claude
1.1. Architectural Innovations in GPT-5.5
GPT-5.5 represents a significant milestone in the evolution of transformer-based language models. Building upon the successes of GPT-4 and earlier versions, GPT-5.5 introduces a series of architectural enhancements that profoundly impact its ability to process, understand, and generate language.
For additional context on this topic, see our detailed coverage of ChatGPT Prompts.
Key among these innovations is the introduction of advanced sparse attention mechanisms, which allow the model to efficiently attend to relevant tokens across extremely long contexts without compromising computational feasibility. This results in enhanced memory capabilities, enabling GPT-5.5 to maintain coherent responses over tens of thousands of tokens. Such an extended context window surpasses previous limits and opens new possibilities for applications involving extensive documents, multi-turn dialogues, and complex reasoning tasks.
Moreover, GPT-5.5 incorporates a hybrid training approach combining supervised learning with reinforcement learning from human feedback (RLHF) and self-supervised continual learning. This mixture enhances its alignment with human values and preferences, ensuring more accurate and contextually appropriate outputs.
From a prompting perspective, these architectural advancements mean that prompt engineers can design significantly more complex and layered prompts without fearing context truncation. The model’s enhanced token handling allows for embedding detailed instructions, multi-step reasoning chains, and richer context sources directly within the prompt, thereby improving response quality and relevance.
1.2. Claude’s Unique Strengths in 2026
Claude in 2026 has evolved with a distinctive focus on interpretability, safety, and multimodal integration. Unlike other LLMs that prioritize raw generative performance, Claude emphasizes producing responses that are not only accurate but also explainable and ethically aligned. Its architecture integrates advanced safety filters and bias mitigation modules, making it a preferred choice for sensitive applications such as healthcare, legal advisory, and educational tools.
Another standout feature of Claude is its multimodal-context integration capabilities. Claude can process and reason across heterogeneous inputs—text, images, audio snippets, and structured data—within a single session. This multimodality enables use cases such as interactive document analysis, where text and images are analyzed cohesively, or customer support bots that interpret screenshots alongside user queries.
In terms of prompt responsiveness, Claude exhibits a more conservative and reflective generation style. It often prefers to clarify ambiguous prompts and requests additional context when necessary, contrasting with GPT-5.5’s more fluid but occasionally riskier outputs. This behavioral difference necessitates tailored prompting strategies: prompts for Claude should emphasize clarity, explicit instructions, and stepwise queries to fully leverage its strengths.
1.3. How These Models Handle Context and Reasoning
Both GPT-5.5 and Claude demonstrate remarkable improvements in long-context understanding. Their architectures are designed to handle extended sequences of text—far beyond the typical 4,000 to 8,000 token limits of earlier models—enabling them to maintain context over entire documents, dialogues, or datasets.
Internally, these models incorporate enhanced reasoning mechanisms that simulate multi-step logical deduction, hypothesis testing, and error checking. These improvements are reflected in their ability to follow complex instructions, solve intricate problems, and generate explanations for their outputs. This capacity drastically changes the landscape of prompt engineering, as it invites the deployment of advanced prompting frameworks that explicitly leverage the model’s reasoning faculties.
For prompt engineers, understanding these models’ handling of context and reasoning is critical. It allows the crafting of prompts that guide the AI through multi-stage cognitive processes instead of expecting a single-step answer. Such prompts might include explicit reasoning cues, decomposed problem statements, and validation steps—all designed to align with the model’s internal mechanisms.
These foundational insights set the stage for exploring advanced prompting techniques such as Chain-of-Thought prompting and the R-T-C-F framework, which are tailored to exploit the unique capabilities of GPT-5.5 and Claude in 2026.
For additional context on this topic, see our detailed coverage of Claude 3.5.
2. Mastering Chain-of-Thought Prompting
2.1. What is Chain-of-Thought (CoT) Prompting?
Chain-of-Thought (CoT) prompting is a transformative approach to enhancing the reasoning capabilities of large language models. Historically, language models were prompted with questions or instructions expecting direct answers. However, complex reasoning tasks—such as multi-step arithmetic, logical deduction, or problem-solving—often require the model to simulate stepwise thought processes.
CoT prompting addresses this by encouraging the model to articulate intermediate reasoning steps, effectively “thinking aloud” before arriving at a final answer. This explicit decomposition of the problem into smaller, manageable components improves accuracy, transparency, and interpretability.
The concept gained prominence with studies demonstrating that LLMs’ performance on challenging tasks improves significantly when prompted to generate reasoning chains. In 2026, with models like GPT-5.5 and Claude, CoT prompting is no longer optional but essential for leveraging their full reasoning power.
2.2. Implementing CoT in GPT-5.5 and Claude
Implementing effective Chain-of-Thought prompts requires a structured approach. The following step-by-step guide outlines the process:
- Introduce the Problem Clearly: Begin with a concise but unambiguous statement of the problem or question.
- Request Explicit Reasoning: Prompt the model to explain its reasoning process before providing an answer, e.g., “Let’s think through this step-by-step.”
- Decompose Complex Problems: Break multi-step problems into sequential components, guiding the model to tackle each part in order.
- Provide Exemplars: Incorporate examples demonstrating chain-of-thought reasoning to prime the model’s response style.
- Encourage Verification: Ask the model to verify intermediate results or re-check calculations before finalizing answers.
Here is an example of a CoT prompt tailored for GPT-5.5 addressing a math problem:
Q: If a train travels 60 miles in 1.5 hours, what is its average speed in miles per hour? Let's think step-by-step. A: First, calculate the average speed by dividing the total distance by the total time. The train traveled 60 miles in 1.5 hours. So, 60 ÷ 1.5 = 40 miles per hour. Therefore, the average speed is 40 mph.
Similarly, for Claude, a CoT prompt might emphasize clarity and cautious reasoning:
Q: Determine the logical conclusion: If all birds can fly and penguins are birds, can penguins fly? Please explain your reasoning step-by-step. A: Let's analyze the statements carefully. First, the premise says all birds can fly. Next, penguins are classified as birds. However, we know from real-world knowledge that penguins cannot fly. This indicates the initial premise is not universally true. Therefore, the conclusion that penguins can fly is false.
2.3. Tips for Maximizing CoT Effectiveness
- Use Explicit Reasoning Cues: Phrases like “step-by-step,” “first,” “then,” and “finally” signal the model to structure its output logically.
- Gradual Decomposition: Avoid overwhelming the model by breaking down problems into smaller sub-questions within the prompt.
- Leverage Model-Specific Strengths: GPT-5.5 excels in fluid multi-step reasoning, while Claude benefits from prompts that encourage cautious and explicit validation.
- Incorporate Examples: Providing few-shot examples of chain-of-thought reasoning primes the model to adopt the desired reasoning style.
- Maintain Prompt Clarity: Avoid ambiguous or overly complex language that might confuse the model during reasoning.
2.4. Common Pitfalls and How to Avoid Them
While CoT prompting is powerful, practitioners must be aware of potential pitfalls:
| Common Pitfall | Description | Mitigation Strategy |
|---|---|---|
| Overloading the Prompt | Including excessive irrelevant details can confuse the model and dilute focus. | Keep prompts concise and focused on the essential reasoning steps. |
| Ambiguous Step Transitions | Vague or unclear transitions between reasoning steps may cause logical breaks. | Use explicit transition phrases and numbering to structure reasoning clearly. |
| Handling Hallucinations | The model may fabricate facts or steps during reasoning. | Prompt for verification steps and encourage self-checks to reduce hallucinations. |
By carefully designing Chain-of-Thought prompts and avoiding these pitfalls, users can significantly enhance the reasoning accuracy of GPT-5.5 and Claude.
For additional context on this topic, see our detailed coverage of OpenAI API.
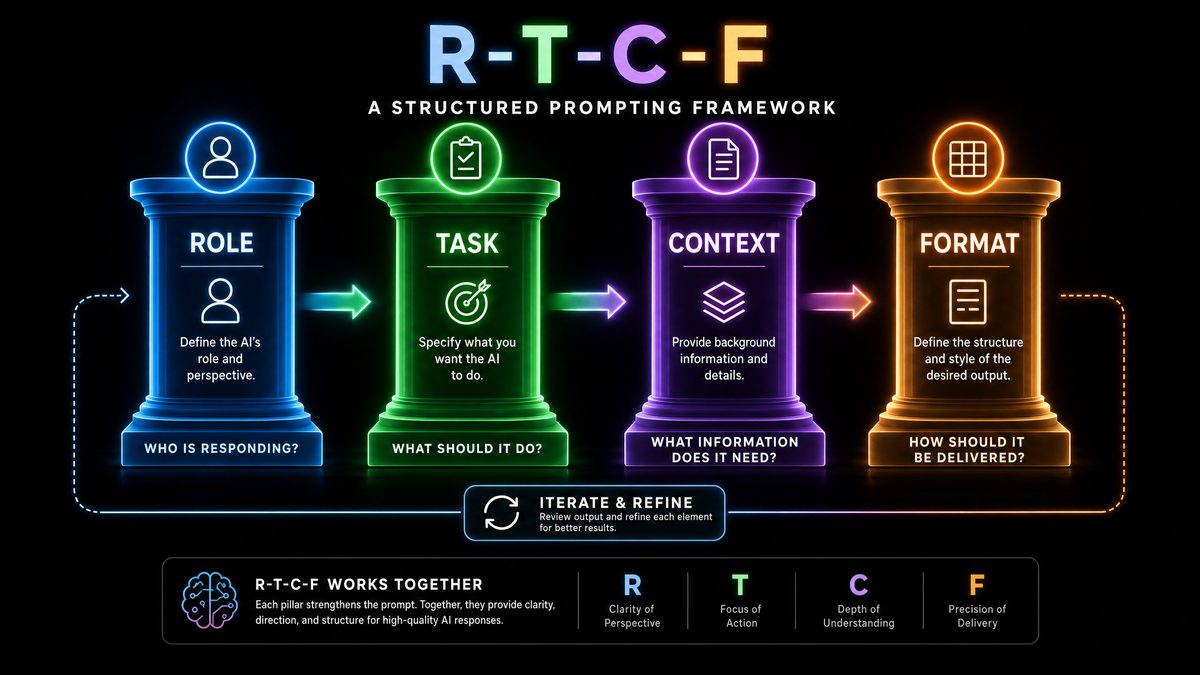
3. The R-T-C-F Framework for Structured Prompting
3.1. Introduction to the R-T-C-F Framework
The R-T-C-F framework is a cutting-edge prompting methodology designed to harness the full power of GPT-5.5 and Claude by structuring the cognitive flow within prompts. The acronym stands for:
- Retrieve: Extract relevant information from external or internal knowledge sources.
- Think: Engage in internal reasoning and hypothesis formation.
- Compose: Synthesize findings and reasoning into coherent responses.
- Finalize: Validate, confirm, and polish the output.
Rooted in cognitive science and AI interpretability research, R-T-C-F encourages modular prompt design that mirrors human problem-solving stages. This framework enables more reliable, transparent, and adaptable AI outputs.
3.2. Step 1: Retrieve
The first stage involves gathering pertinent information relevant to the query. This retrieval can be internal—leveraging the model’s pretrained knowledge—or external, by integrating APIs, databases, or knowledge graphs.
Techniques include:
- Embedding Retrieval: Using vector similarity search to find related documents or data snippets.
- External Knowledge Bases: Querying domain-specific datasets or live knowledge sources.
- Prompting for Recall: Designing prompts that explicitly instruct the model to recall specific facts or prior context.
For example, a prompt might begin with, “Based on the latest research on renewable energy, retrieve the top three methods currently in use.”
3.3. Step 2: Think
Following retrieval, the model is guided to analyze and reason over the collected information. This phase emphasizes critical thinking, hypothesis generation, and internal validation.
Key approaches include:
- Reflective Prompting: Asking the model to consider multiple perspectives or counterarguments.
- Hypothesis Formation: Encouraging the generation of possible explanations or solutions.
- Uncertainty Quantification: Prompting the model to express confidence levels or indicate areas of doubt.
Example prompt snippet: “Consider the implications of these data points and reason about their impact on climate change mitigation.”
3.4. Step 3: Compose
In this stage, the model synthesizes the insights from retrieval and reasoning into a coherent, logically structured response. Composition requires maintaining narrative flow, clarity, and alignment with user intent.
Best practices for the Compose step include:
- Clear Instruction: Specify the desired format, tone, and level of detail.
- Logical Organization: Encourage grouping related points and using transitions.
- Conciseness: Avoid unnecessary verbosity while preserving nuance.
For example, “Compose a brief executive summary highlighting the key findings and recommendations.”
3.5. Step 4: Finalize
The final phase involves validation and refinement, ensuring the answer is accurate, complete, and free of errors. This may include self-checks, error correction prompts, or requests for alternative formulations.
Techniques to reinforce Finalize include:
- Self-Verification: Prompt the model to review and confirm its answer.
- Error Detection: Ask for identification and correction of potential mistakes.
- Polishing: Request rewriting for clarity, style, or conciseness.
Example: “Please review your response for accuracy and rephrase any ambiguous statements.”
3.6. Applying R-T-C-F in Real-World Use Cases
The R-T-C-F framework shines in a variety of applications, enabling robust AI solutions:
| Use Case | Description | R-T-C-F Application |
|---|---|---|
| Customer Support Automation | Automating responses to user inquiries with accuracy and empathy. |
|
| Research Summarization | Generating concise summaries from large scientific documents. |
|
| Creative Writing Assistance | Supporting authors with story development and editing. |
|
4. Few-Shot Prompting: Elevating Model Performance with Minimal Examples
4.1. Fundamentals of Few-Shot Learning in Language Models
Few-shot prompting is a paradigm wherein the model is provided with a small number of examples within the prompt to guide its response to a new query. This contrasts with zero-shot prompting, which provides no examples, and one-shot prompting, which offers a single example.
Few-shot learning is critical for GPT-5.5 and Claude because these models can generalize effectively from minimal demonstrations, enabling rapid adaptation to diverse tasks without retraining. By carefully selecting examples, prompt engineers can steer the model’s behavior, style, and accuracy, especially for specialized or domain-specific tasks.
4.2. Designing Effective Few-Shot Examples
Effective few-shot examples share several attributes:
- Representative: Examples should closely mirror the task structure and complexity of the target query.
- Diverse: Including a range of scenarios prevents overfitting to a narrow pattern.
- Clear and Concise: Avoid unnecessary verbosity to maximize prompt space.
- Consistent Formatting: Uniform style and structure aid model learning.
Here is a sample few-shot prompt designed for GPT-5.5 to classify customer feedback sentiment:
Example 1: "The product quality was excellent and exceeded my expectations." → Positive Example 2: "I am disappointed with the delayed delivery." → Negative Example 3: "Customer service was helpful but the issue remains unresolved." → Neutral Classify the sentiment: "The new update improved the app's performance significantly."
By providing diverse and clear examples, the model can infer the underlying task and respond accurately.
4.3. Context Window Utilization and Management
Although GPT-5.5 and Claude support extended context windows, prompt engineers must still manage token limits prudently. Effective context window management involves strategies such as:
- Prioritization: Include only the most relevant few-shot examples and contextual information.
- Chaining Prompts: Break complex tasks into multiple prompt exchanges, preserving state externally.
- Dynamic Truncation: Automate the selection and truncation of historical context to optimize token usage.
For example, in multi-turn conversations, it may be necessary to summarize past dialogue briefly rather than including full verbatim history.
4.4. Advanced Few-Shot Techniques
Beyond static example sets, advanced techniques include:
- Dynamic Example Selection: Algorithms select the most relevant few-shot examples based on the current query’s semantic similarity.
- Meta-Prompting: Using higher-level instructions that guide the model on how to interpret and adapt examples.
- Adaptive Prompt Length: Varying the number and complexity of examples based on task difficulty and context constraints.
These approaches maximize model adaptability and output quality, especially in complex or evolving domains.
5. Contextual Reasoning in the Latest Models
5.1. Defining Contextual Reasoning
Contextual reasoning transcends mere context awareness by enabling models to interpret and act upon nuanced, implicit, and evolving information within a given interaction. It involves understanding subtleties such as tone, implied intentions, background knowledge, and interdependencies between statements.
This capability is essential for decision-making, complex problem-solving, and human-like dialogue continuity. GPT-5.5 and Claude have significantly advanced contextual reasoning, enabling AI systems to function more naturally and effectively in dynamic environments.
5.2. Leveraging Extended Context Windows
Both models’ support for extended context windows allows prompt designers to include large amounts of relevant data—past conversation turns, detailed instructions, or external documents—directly in the prompt.
To maximize context retention:
- Organize Context Logically: Present information in chronological or thematic order.
- Use Summaries: Condense older context into concise summaries to save tokens.
- Explicit Reference: Use explicit pointers (“As mentioned earlier,” “In section 2,” etc.) to help the model connect dots.
5.3. Multi-Turn Dialogues and Contextual Memory
Maintaining conversational state over multiple turns is challenging but critical for coherent interactions. Techniques include:
- Persistent Context Storage: Saving dialogue history externally and selectively reinserting essential parts.
- Prompt Templates: Structured templates that maintain role distinctions, user intents, and system instructions.
- Context Refreshing: Periodically summarizing or revalidating context to prevent drift.
For example, a customer support bot using Claude may use a prompt template that begins each reply with, “Based on your previous messages, here is the next step…” ensuring relevance and continuity.
5.4. Handling Ambiguity and Implicit Context
Ambiguous prompts or implicit context can degrade model performance. Strategies to mitigate this include:
- Clarification Prompts: Requesting the model to ask follow-up questions when ambiguity is detected.
- Context Enrichment: Providing additional background information or examples.
- Iterative Refinement: Using multiple prompt iterations to gradually clarify and expand the context.
These techniques help transform vague inputs into well-defined queries, improving output relevance and accuracy.

6. Comparative Analysis: GPT-5.5 vs Claude Prompting Approaches
While GPT-5.5 and Claude share a common lineage in transformer-based architecture, their prompting approaches reflect differences in design philosophy, safety emphasis, and multimodal integration.
| Aspect | GPT-5.5 | Claude |
|---|---|---|
| Chain-of-Thought Reasoning |
|
|
| R-T-C-F Framework Application |
|
|
| Few-Shot Prompting Nuances |
|
|
| Contextual Reasoning Capabilities |
|
|
Choosing between GPT-5.5 and Claude for prompting depends heavily on the application domain, desired output style, and safety requirements. Understanding their distinctive prompting nuances enables optimal model selection and prompt design.
7. Practical Prompt Engineering: Tools and Best Practices
7.1. Prompt Debugging and Iterative Refinement
Effective prompt engineering is an iterative process involving continuous testing, evaluation, and refinement. Techniques for debugging prompts include:
- Output Analysis: Systematically reviewing model responses to identify recurring errors or inconsistencies.
- Incremental Prompt Modification: Changing one element at a time to isolate effects.
- Feedback Loops: Integrating user or expert feedback to guide prompt adjustments.
Tools such as prompt playgrounds, logging utilities, and automated evaluation scripts are invaluable for managing this cycle.
7.2. Automation and Prompt Generation Tools
Recent advancements have introduced software platforms that automate prompt generation and optimization. These tools often provide:
- Template Libraries: Predefined prompt structures for common tasks.
- API Integrations: Seamless connection with models like GPT-5.5 and Claude for real-time testing.
- Performance Analytics: Metrics on prompt effectiveness and output quality.
Incorporating these tools accelerates prompt engineering workflows and ensures consistent quality.
7.3. Ethical Considerations and Bias Mitigation
Prompt engineers must be vigilant about ethical implications, including:
- Fairness: Designing prompts that avoid reinforcing stereotypes or biases.
- Transparency: Ensuring users understand AI limitations and decision processes.
- Harm Avoidance: Steering the model away from generating harmful or inappropriate content.
Techniques include bias audits, prompt sanitization, and incorporating safety layers within prompt structures. Both GPT-5.5 and Claude provide tools and guidelines to support ethical prompt design.
8. Future Directions: Beyond 2026 Prompting Frameworks
8.1. Anticipated Advances in Prompting Techniques
The future of prompting is poised for breakthroughs including:
- Adaptive and Self-Optimizing Prompts: Prompts that evolve dynamically based on model feedback and task performance.
- Multimodal Integration: Seamless prompting that incorporates text, images, video, and sensor data.
- Context-Aware Prompt Generation: AI systems that generate context-specific prompts autonomously.
These advances will push the boundaries of AI usability and intelligence.
8.2. The Role of Human-in-the-Loop Prompting
Human-in-the-loop (HITL) approaches remain critical to balancing automation with human judgment. Collaborative prompting strategies allow humans to guide, correct, and refine AI outputs in real-time, ensuring higher quality and ethical alignment.
HITL fosters transparency, accountability, and adaptability, particularly in high-stakes domains.
8.3. Towards Autonomous Prompt Engineering Agents
Looking ahead, autonomous AI agents capable of creating, testing, and refining their own prompts are emerging. These agents will:
- Continuously optimize prompts for specific tasks and contexts.
- Reduce reliance on manual prompt engineering.
- Broaden AI accessibility by lowering technical barriers.
The integration of such agents promises to democratize AI usage and accelerate innovation.
Useful Links
- OpenAI Research
- Anthropic – Claude AI
- Chain-of-Thought Prompting Paper
- Few-Shot Learning with Transformers
- DeepMind’s LaMDA Research
- Google AI Blog: Contextual Understanding
- OpenAI Cookbook – Prompt Engineering
- R-T-C-F Framework Overview
- Ethics in AI Prompting
For readers interested in deepening their knowledge, these resources provide foundational research, practical tools, and ethical guidelines relevant to advanced prompting techniques.
Appendix
Sample Prompts Illustrating Each Technique
- Chain-of-Thought Prompt Example:
Q: Calculate the sum of the first five prime numbers. Please explain your reasoning step-by-step. A: The first five prime numbers are 2, 3, 5, 7, and 11. Adding them together: 2 + 3 = 5, 5 + 5 = 10, 10 + 7 = 17, 17 + 11 = 28. Therefore, the sum is 28. - R-T-C-F Prompt Example:
Retrieve relevant data on electric vehicle battery lifespan. Think about factors affecting battery degradation. Compose a summary highlighting key points. Finalize by checking for accuracy and completeness. - Few-Shot Prompt Example:
Example 1: Translate English to French: "Good morning" → "Bonjour" Example 2: Translate English to French: "Thank you" → "Merci" Translate: "How are you?" - Contextual Reasoning Prompt Example:
User: I am feeling cold and my throat hurts. Assistant: Given these symptoms and the current season, it might be a common cold. Would you like advice on home remedies or should I help you find a nearby clinic?
Glossary of Key Terms
| Term | Definition |
|---|---|
| Chain-of-Thought (CoT) Prompting | A prompting technique encouraging models to articulate intermediate reasoning steps explicitly. |
| R-T-C-F Framework | A four-stage prompting methodology: Retrieve, Think, Compose, Finalize. |
| Few-Shot Prompting | Providing a small number of examples within a prompt to guide model responses. |
| Contextual Reasoning | The ability of a model to interpret and act upon nuanced and evolving context beyond surface-level awareness. |
| Embedding Retrieval | A technique to find relevant documents or data by comparing vector representations of text. |
| Multimodal Integration | The ability to process and reason using multiple data modalities such as text, images, and audio. |
Understanding these terms is fundamental to mastering the advanced prompting techniques discussed throughout this article.