OpenAI Guaranteed Capacity: How Enterprises Can Now Secure Long-Term AI Compute

What Is OpenAI Guaranteed Capacity
On May 19, 2026, OpenAI introduced a groundbreaking enterprise offering known as OpenAI Guaranteed Capacity, designed to transform how organizations access and manage AI compute resources. This initiative allows enterprises to secure dedicated, long-term access to OpenAI’s powerful GPU infrastructure through flexible commitments starting at one year and extending beyond. By addressing critical concerns around availability, scalability, and cost predictability, OpenAI Guaranteed Capacity represents a strategic evolution in AI compute provisioning tailored to the unique demands of large-scale business operations.
The Strategic Importance of Compute Capacity
In recent years, compute has evolved from a mere operational input to a strategic asset for enterprises leveraging AI technologies. Advanced AI workloads, including large language models (LLMs), generative AI, and real-time inference, require consistent and high-volume GPU availability. Enterprises building AI-driven products, services, or analytics pipelines cannot afford unpredictable access or throttling, especially during periods of peak demand. Traditional pay-as-you-go API models, while flexible, often fall short in providing the reliability and performance guarantees necessary for mission-critical applications.
OpenAI Guaranteed Capacity directly addresses these pain points by enabling organizations to reserve a dedicated slice of OpenAI’s GPU infrastructure. This reserved capacity ensures that enterprises have uninterrupted access to the compute resources needed to run their AI workloads at scale without the risk of sudden rate limits or downtime. By securing compute upfront, businesses can plan and execute AI initiatives with confidence, aligning resource availability with product roadmaps and customer expectations.
Commitment Terms and Pricing Models
The core offering under OpenAI Guaranteed Capacity revolves around multi-term commitments, starting from a minimum of one year. Enterprises can select commitment durations that best fit their operational timelines and growth projections, with options extending beyond one year for longer-term strategic planning. This flexibility allows companies to balance upfront investment with the benefits of guaranteed availability and preferential pricing.
Pricing is carefully calibrated based on two primary factors:
- Commitment Length: Longer commitments benefit from tiered discounts, incentivizing enterprises to lock in capacity over extended periods. For example, a 3-year commitment may reduce per-GPU-hour costs by approximately 15-25% compared to a single-year contract.
- Volume of Reserved Capacity: Enterprises reserving larger blocks of GPU capacity—whether for training large models or powering high-volume inference—receive further economies of scale. Volume discounts can scale incrementally based on reserved GPU count, providing cost efficiencies for sizable AI deployments.
This pricing structure fosters predictability in AI compute budgeting, enabling finance and engineering teams to align expenditures with strategic growth. It also contrasts with traditional on-demand pricing models, which are subject to market-driven fluctuations and potential price spikes during usage surges.
Addressing Enterprise Concerns: Availability and Rate Limits
One of the most pressing challenges for enterprises using AI APIs is managing availability and rate limits during periods of high demand. Organizations building products with embedded AI capabilities often face unpredictable API throttling, which can degrade user experience or stall critical workflows. This challenge is exacerbated when multiple teams or applications compete for finite compute resources within the same cloud environment.
OpenAI Guaranteed Capacity mitigates these risks by providing a dedicated pool of GPU resources isolated from the broader shared environment. Enterprises no longer compete with peak public demand fluctuations or other customers’ workloads. Instead, they benefit from:
- Consistent API Throughput: Predictable request rates aligned with reserved capacity limits, ensuring smooth application performance.
- Reduced Latency: Priority routing and optimized resource allocation within OpenAI’s infrastructure to minimize response times.
- Service-Level Agreements (SLAs): Formal commitments guaranteeing uptime and access levels tailored to enterprise requirements.
By guaranteeing access to compute resources, enterprises can architect highly reliable AI-powered systems without compensating for resource contention or unpredictable service interruptions. This capability is critical for industries such as finance, healthcare, and manufacturing, where AI availability directly impacts operational continuity and compliance obligations.
Use Case Examples Illustrating the Value of Guaranteed Capacity
Consider a financial services firm deploying a real-time AI risk assessment engine that evaluates thousands of transactions per second. Any API latency or throttling could lead to delayed fraud detection or compliance breaches. By securing OpenAI Guaranteed Capacity, the firm ensures dedicated GPU resources are always available to process these transactions within strict timeframes.
Similarly, a global consumer electronics company integrating generative AI into its customer support chatbots can rely on guaranteed capacity to maintain high-quality, uninterrupted conversational experiences during product launches or promotional events, when user traffic spikes dramatically.
These examples underscore how OpenAI Guaranteed Capacity empowers enterprises to move beyond reactive, usage-based AI consumption toward proactive capacity planning and operational excellence.
Why Compute Access Is Now a Strategic Priority
The Rising Importance of AI Compute in Enterprise Strategy
In the rapidly evolving landscape of artificial intelligence, compute resources have transformed from a mere technical necessity into a critical strategic asset for enterprises. The announcement of OpenAI Guaranteed Capacity on May 19, 2026, highlights this fundamental shift. Enterprises now face unprecedented demand for high-performance AI models, making consistent and reliable access to compute resources not just beneficial but essential to maintaining competitive advantage.
Historically, enterprises accessed AI models via shared cloud APIs, which, while flexible, come with inherent limitations such as rate limits and unpredictable availability during peak demand. As AI workloads scale, these constraints translate into operational bottlenecks, increased latency, and potential interruptions in service delivery. Consequently, organizations are prioritizing guaranteed compute access to ensure uninterrupted AI-driven workflows, ranging from real-time customer service automation to large-scale data analytics.
Dedicated GPU Capacity: A Game-Changer for Enterprise AI
OpenAI Guaranteed Capacity enables enterprises to reserve dedicated GPU capacity with commitments starting from one year or longer. This offering addresses core enterprise concerns by providing predictable, scalable infrastructure tailored to the unique demands of large-scale AI applications. Dedicated GPUs mean that organizations no longer compete with other users for compute time, effectively eliminating API rate limits and availability uncertainty.
For example, a multinational financial institution leveraging AI for fraud detection can anchor its critical processes on a reserved compute infrastructure, ensuring zero downtime even during market surges or global events that cause spikes in transaction volumes. Similarly, a healthcare provider deploying AI for diagnostic imaging analysis can guarantee consistent throughput and compliance with stringent latency requirements.
This model also provides financial predictability. Pricing is structured based on commitment duration and volume, allowing enterprises to optimize costs through longer-term contracts while securing the compute power necessary for their AI initiatives. The flexibility in contract length—from one year and beyond—enables organizations to align their AI infrastructure investments with strategic roadmaps and budgeting cycles.
Addressing Enterprise Concerns: Availability, Performance, and Compliance
One of the major barriers to enterprise AI adoption has been the unpredictability of cloud AI service availability. During periods of peak demand or global events, shared API services can throttle requests or delay processing, negatively impacting critical business operations. OpenAI Guaranteed Capacity directly addresses these challenges by granting prioritized access, effectively removing these limitations and providing a dedicated pipeline to OpenAI’s powerful models.
Moreover, dedicated compute enhances compliance capabilities. Enterprises in regulated industries such as finance, healthcare, and government require not only performance guarantees but also control over data residency and processing environments. Securing dedicated GPU resources under a contractual agreement enables closer alignment with rigorous compliance frameworks, reducing risks associated with data sovereignty and auditability.
Consider a large retail chain that uses AI-driven demand forecasting to optimize inventory. With guaranteed capacity, the chain can confidently run continuous, intensive prediction models without fear of throttling or downtime, ensuring shelves are stocked optimally, reducing waste, and maximizing revenue.
Strategic Implications for AI Deployment and Innovation
Compute access is becoming integral to enterprise AI strategies, influencing how organizations design, deploy, and scale their AI solutions. With guaranteed capacity, enterprises gain the freedom to innovate without infrastructure constraints, enabling new use cases that were previously impractical due to compute uncertainty.
For instance, real-time language translation services for global customer support, advanced generative design in manufacturing, and complex multi-modal AI applications integrating vision, text, and audio can all rely on stable, dedicated GPUs to operate seamlessly.
Furthermore, the commitment model fosters deeper partnerships between enterprises and OpenAI, facilitating co-development opportunities and tailored support to optimize AI workloads. This alignment accelerates time to value and ensures that compute capacity evolves in step with emerging AI trends and enterprise needs.
For organizations interested in how reserved compute capacity intersects with AI model optimization and deployment strategies, exploring concepts like model fine-tuning and inference efficiency can provide further insight. This approach can be explored in more depth in our related discussion on advanced AI deployment strategies, which delves into how enterprises maximize the impact of their compute investments while maintaining agility Enterprise AI Automation Case Studies 2026: How Companies Are Using AI Agents to Transform Operations.
Summary Table: Traditional API Access vs. OpenAI Guaranteed Capacity
| Aspect | Traditional Shared API Access | OpenAI Guaranteed Capacity |
|---|---|---|
| Compute Access | Shared, subject to rate limits and availability fluctuations | Dedicated GPU capacity reserved for enterprise |
| Commitment | Pay-as-you-go, no long-term commitment | 1 year or longer commitments; volume-based pricing |
| Availability | Potentially throttled during peak demand periods | Guaranteed availability with priority access |
| Performance | Variable, dependent on shared infrastructure load | Consistent high-performance compute resources |
| Compliance | Limited control over data processing environments | Enhanced control supporting regulatory compliance |
| Use Cases | Suitable for experimentation, low to moderate workloads | Ideal for mission-critical, large-scale AI deployments |
How the Program Works: Commitment Tiers and Pricing
OpenAI Guaranteed Capacity is designed to offer enterprises a reliable and predictable solution to secure AI compute resources over extended periods. As AI workloads become increasingly critical to business operations, unpredictable API availability or rate limits can introduce unacceptable risks. This program addresses those challenges by allowing organizations to reserve dedicated GPU capacity through multi-year commitments, ensuring uninterrupted access to compute power tailored to enterprise needs.
Commitment Tiers: Flexible Options for Diverse Enterprise Needs
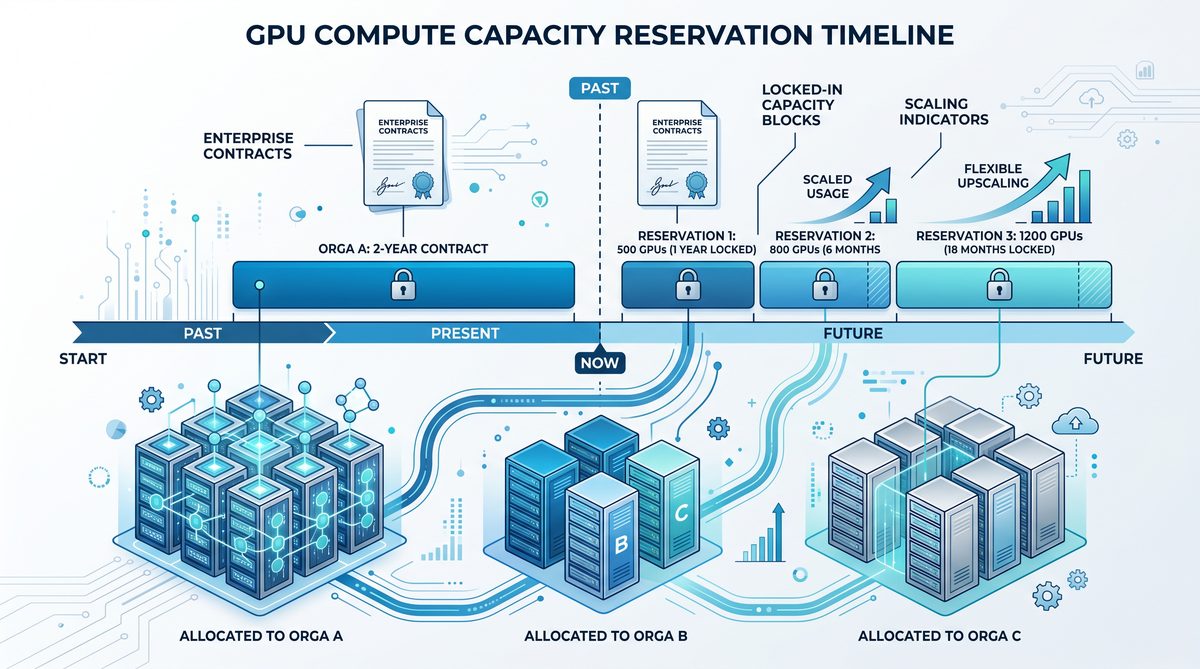
Enterprises can choose from several commitment tiers based on the duration and volume of compute resources they require. The program currently offers commitment lengths starting at one year, with options extending up to three years or more, allowing companies to align their AI infrastructure planning with their strategic roadmaps.
Each tier is structured to provide a guaranteed allocation of GPU hours per month, with higher tiers offering proportionally larger dedicated capacity. This tiered approach caters to a wide range of use cases—from companies running pilot projects requiring moderate GPU time, to large-scale deployments powering real-time AI services with intensive compute demands.
- Silver Tier: 1-year commitment with a minimum allocation of 500 GPU hours per month.
- Gold Tier: 2-year commitment with at least 2,000 GPU hours monthly, suitable for medium to large enterprises.
- Platinum Tier: 3-year or longer commitment, guaranteeing 5,000+ GPU hours per month, ideal for organizations with heavy AI workloads and mission-critical applications.
This tiered commitment model enables enterprises to optimize costs by selecting the capacity that aligns with their AI scale and workload growth expectations. Additionally, customers can scale their allocations annually within their commitment term, providing flexibility to accommodate evolving compute demands.
Pricing Structure: Balancing Volume, Duration, and Predictability
Pricing under OpenAI Guaranteed Capacity is primarily influenced by two factors: the length of the commitment and the volume of GPU resources reserved. Longer commitments and higher volumes unlock more favorable pricing per GPU hour, reflecting the economies of scale and the value of predictable demand for OpenAI’s infrastructure planning.
| Commitment Tier | Commitment Length | Monthly GPU Hours | Price per GPU Hour (USD) | Effective Monthly Cost (USD) |
|---|---|---|---|---|
| Silver | 1 year | 500 | $1.20 | $600 |
| Gold | 2 years | 2,000 | $1.05 | $2,100 |
| Platinum | 3 years | 5,000+ | $0.90 | $4,500+ |
For example, a technology firm requiring sustained high-volume access might opt for the Platinum Tier with a 3-year commitment, securing compute hours at $0.90 per GPU hour—25% less than the Silver Tier rate for a 1-year commitment. This pricing model incentivizes long-term planning and commitment while providing enterprises with clear cost predictability.
Moreover, the program includes provisions for volume-based discounts beyond the baseline monthly GPU hours. Enterprises can negotiate customized agreements to accommodate fluctuating workloads, with pricing adjustments reflecting seasonal or project-specific compute needs.
Addressing Enterprise Concerns: Availability, Rate Limits, and Predictability
One of the key motivations behind OpenAI Guaranteed Capacity is to mitigate the impact of API rate limits and availability constraints, which can be especially problematic during periods of peak demand or major product launches. By reserving dedicated GPU capacity, enterprises gain exclusive access that is not shared with other customers, drastically reducing latency and improving service reliability.
For example, an e-commerce company planning a seasonal AI-driven recommendation campaign can rely on guaranteed capacity to handle sudden spikes in query volume without degradation of response times or throttling due to rate limits. This level of assurance transforms AI compute from a variable operational expense into a manageable, strategic asset.
Furthermore, the program incorporates service-level agreements (SLAs) that guarantee uptime and response performance, providing enterprises with contractual recourse if capacity availability falls below agreed thresholds. This is a critical feature for sectors such as finance, healthcare, and manufacturing, where AI-driven insights must be delivered consistently and securely.
By integrating these elements—tiered commitments, transparent pricing, dedicated compute allocations, and robust SLAs—OpenAI Guaranteed Capacity empowers enterprises to confidently embed AI compute into their core infrastructure with long-term stability and cost efficiency.
Who Should Consider Guaranteed Capacity
Enterprises with High-Demand AI Workloads
OpenAI Guaranteed Capacity is primarily designed for enterprises that rely heavily on AI-driven applications and require uninterrupted, scalable compute resources. Organizations operating in sectors such as finance, healthcare, automotive, and retail increasingly deploy advanced AI models for critical functions like risk assessment, diagnostic imaging, autonomous vehicle navigation, and personalized customer experiences. These use cases demand consistent access to GPU compute to maintain performance and meet service-level agreements (SLAs).
For example, a financial services company running real-time fraud detection models cannot afford latency spikes or service interruptions caused by compute resource contention. By securing dedicated GPU capacity through OpenAI’s Guaranteed Capacity program, such firms ensure predictable throughput and latency, even during AI usage peaks. This mitigates risks associated with API rate limits or degraded performance during high-volume periods, which are common in shared cloud environments.
Organizations Planning Long-Term AI Investments
Another key audience for Guaranteed Capacity comprises businesses with strategic, long-term AI initiatives. With the AI compute landscape evolving rapidly, enterprises are increasingly viewing compute resources as a foundational asset rather than a variable expense. Committing to one-year or multi-year capacity contracts enables these organizations to forecast costs accurately and align infrastructure investments with their AI roadmap.
For instance, a technology company developing next-generation natural language processing solutions may plan to scale model training and inference workloads over several years. Locking in guaranteed GPU access at a predictable price point allows the company to optimize budgeting and avoid the volatility associated with spot pricing or on-demand capacity fluctuations. This financial predictability supports initiatives such as multi-modal AI research or large-scale generative AI deployments, which require sustained computational throughput at scale.
Enterprises Facing Peak Usage and Availability Challenges
Many enterprises encounter operational challenges around AI API availability during peak demand intervals, particularly when using shared cloud compute resources. These challenges include hitting rate limits, experiencing throttling, or encountering increased latency, which can disrupt production workflows and degrade user experience.
OpenAI Guaranteed Capacity addresses these issues by allocating dedicated GPU resources exclusively to the customer, effectively eliminating contention with other users. This is crucial for companies running mission-critical applications where AI service interruptions can have serious business consequences. For example, an e-commerce platform using AI-powered recommendation engines during high-traffic shopping events needs guaranteed compute capacity to handle surges in user queries without performance degradation.
Furthermore, Guaranteed Capacity supports enterprises in meeting internal governance and compliance requirements related to data security and operational consistency. By reserving dedicated infrastructure, organizations can better manage data flows and auditability, essential for regulated industries such as healthcare and financial services.
Businesses Looking for Flexible Commitment Options
OpenAI’s offering provides flexibility through tiered commitment lengths and volume-based pricing, making it accessible to a wide range of enterprise sizes and use cases. Companies can commit to a minimum of one year, with options to extend commitments based on evolving compute needs. This flexibility allows businesses to scale their AI capabilities while optimizing their capital expenditures.
For example, a midsize software firm entering the AI market can start with a one-year commitment to evaluate workload patterns and then expand capacity as adoption grows. Conversely, large multinational corporations may negotiate multi-year agreements to secure the most favorable pricing and ensure uninterrupted AI compute availability across global operations.
Integration with Broader AI Infrastructure Strategies
Finally, enterprises integrating AI into their broader cloud and on-premises infrastructure strategies will find Guaranteed Capacity an attractive proposition. By combining reserved OpenAI compute capacity with existing hybrid or multi-cloud environments, organizations can architect resilient, high-performance AI platforms that align with business objectives.
This integration is particularly relevant for companies adopting advanced AI concepts such as federated learning, continuous model retraining, or real-time inference at the edge. For a deeper understanding of how AI infrastructure choices impact enterprise AI strategies, consider exploring related topics such as AI model deployment architectures and infrastructure optimization techniques The Complete Guide to OpenAI’s Trusted Access for Cyber Program: Eligibility, Setup, and Workflow Integration.
In summary, OpenAI Guaranteed Capacity is ideally suited for enterprises that prioritize reliability, scalability, and financial predictability in their AI compute resources. By securing long-term, dedicated access to GPU capacity, organizations can confidently scale AI initiatives, mitigate operational risks, and optimize AI-driven innovation.
Comparing OpenAI’s Approach to Other Providers
As the AI compute landscape matures, enterprises are increasingly looking for stable, scalable, and cost-effective solutions to power their AI workloads. OpenAI’s Guaranteed Capacity program, announced on May 19, 2026, represents a significant evolution in how organizations can secure dedicated AI compute resources over extended periods. To fully appreciate the strategic advantage of OpenAI’s approach, it is essential to compare it with offerings from other leading cloud and AI compute providers such as AWS, Google Cloud, Microsoft Azure, and emerging specialized AI infrastructure companies.
Dedicated Compute Reservations and Commitment Models
OpenAI’s Guaranteed Capacity program allows enterprises to reserve dedicated GPU capacity with commitment lengths starting from one year, scaling up based on volume. This long-term commitment model is designed to provide predictability in both access and pricing, addressing common enterprise concerns around fluctuating availability and rate limits during peak demand periods.
In contrast, major cloud providers like AWS, Google Cloud, and Azure offer reserved instances or committed use discounts that provide cost savings in exchange for a commitment—typically one or three years—but these are often generalized for virtual machines or GPU instances rather than AI-specific compute tailored to models like GPT or DALL·E. For example, AWS’s EC2 Reserved Instances and Savings Plans reduce costs by up to 72% compared to on-demand usage, but they do not guarantee priority access to AI-specific APIs or mitigations against throttling during high traffic.
Moreover, OpenAI’s program is unique in that it couples the hardware reservation with prioritized API access to its suite of generative AI models. This integration ensures that enterprises are not just reserving raw compute but also securing uninterrupted and scalable AI service performance—an increasingly critical factor as generative AI workloads grow in complexity and demand.
Pricing Transparency and Volume-Based Discounts
OpenAI’s pricing model for Guaranteed Capacity is explicitly tied to both the length of the commitment and the volume of compute reserved, allowing enterprises to optimize costs according to their strategic AI initiatives. This tiered pricing structure incentivizes larger, longer-term commitments by offering progressively better rates, making it attractive for companies with substantial AI workloads and predictable usage patterns.
Comparatively, cloud providers typically offer volume discounts for bulk GPU usage, but pricing can be opaque due to the variability of instance types, additional service charges, and the complexity of AI frameworks deployment. For example, Google Cloud’s committed use contracts apply broadly across compute resources, but the effective cost for dedicated AI inference or training workloads depends heavily on instance selection and regional availability. This complexity can make budgeting for AI projects more challenging.
OpenAI’s approach simplifies this by providing a unified pricing model that encompasses both compute hardware and AI model access, which aligns well with enterprise financial planning and reduces the operational overhead of managing disparate contracts and service agreements.
Addressing API Availability and Rate Limits
One of the key enterprise challenges in leveraging public AI APIs is the unpredictability of availability during peak demand periods. Rate limiting and throttling can severely impact mission-critical applications that depend on real-time AI inference. OpenAI’s Guaranteed Capacity directly addresses this by offering reserved capacity that guarantees throughput and latency SLAs aligned with business-critical requirements.
While providers like Microsoft Azure OpenAI Service have made strides in improving API availability, their offerings are still subject to shared infrastructure constraints and throttling policies that can impact performance during traffic spikes. Similarly, specialized AI infrastructure providers may offer dedicated hardware but often lack integrated AI model access or comprehensive SLA commitments for API availability.
OpenAI’s model ensures that enterprises can scale confidently without the risk of degraded service during periods of heavy usage, an advantage that is especially relevant for industries such as finance, healthcare, and retail, where AI-driven decision-making must be continuous and reliable.
Integration with Enterprise AI Ecosystems
Another differentiating factor for OpenAI’s Guaranteed Capacity is its seamless integration with the broader OpenAI ecosystem, including tools for fine-tuning, embeddings, and other advanced AI capabilities. This integration facilitates faster deployment cycles and better alignment between compute resources and AI innovation efforts.
Many enterprises are also exploring hybrid AI architectures that combine on-premises, private cloud, and public cloud resources to meet security and compliance mandates. OpenAI’s offering complements this trend by enabling enterprises to lock in AI compute capacity within a cloud environment while maintaining control over data governance and model customization. This hybrid flexibility is a critical component of modern AI strategies and is touched upon in detail in our article on enterprise AI infrastructure strategies OpenAI Launches GPT-5.5-Cyber: A Specialized Model for Cybersecurity Defenders Protecting Critical Infrastructure.
Summary Comparison Table
| Feature | OpenAI Guaranteed Capacity | AWS Reserved Instances | Google Cloud Committed Use | Azure OpenAI Service |
|---|---|---|---|---|
| Compute Type | Dedicated GPUs optimized for OpenAI models | General-purpose GPU instances (e.g., P4, G5) | General-purpose GPU instances (e.g., A2, T4) | Shared GPU access with AI model APIs |
| Commitment Duration | 1 year minimum, with multi-year options | 1 or 3 years | 1 or 3 years | No long-term commitment; pay-as-you-go |
| API Access Guarantee | Guaranteed prioritized API access with SLAs | No direct API guarantees; separate AI services | No direct API guarantees; separate AI services | API access with potential throttling |
| Pricing Model | Volume and term-based tiered pricing | Discounted hourly rates for reserved usage | Discounted hourly rates for committed use | Pay-as-you-go pricing |
| Enterprise SLAs | Comprehensive SLAs for availability and throughput | Service SLAs for infrastructure only | Service SLAs for infrastructure only | Service SLAs with potential API restrictions |
| Integration | Full integration with OpenAI model ecosystem | General cloud ecosystem integration | General cloud ecosystem integration | Integrated with Azure AI tools |
In conclusion, OpenAI’s Guaranteed Capacity program offers a compelling value proposition for enterprises that require stable, scalable, and cost-effective AI compute with prioritized API access and enterprise-grade SLAs. While other cloud providers offer reserved compute and discounted pricing, none currently provide the integrated, long-term AI compute reservation combined with guaranteed access to advanced OpenAI models. This makes OpenAI’s approach particularly well-suited for organizations seeking to embed generative AI deeply into their core operations with predictable performance and costs.
For enterprises evaluating their AI infrastructure strategies, understanding these nuances is critical to selecting a provider that aligns with both technical needs and business objectives. The evolving competitive landscape will likely see further innovation in this space, but OpenAI’s Guaranteed Capacity sets a new standard for enterprise AI compute availability and reliability.
Markos Symeonides
Implementation Considerations for Enterprise Teams
For enterprise teams looking to integrate OpenAI Guaranteed Capacity into their AI infrastructure, several critical implementation factors must be carefully evaluated to maximize the benefits of this strategic offering. As organizations move beyond ad-hoc API usage toward securing dedicated, long-term compute resources, understanding the operational, financial, and technical implications is essential. This section provides a detailed roadmap to help enterprise teams plan, deploy, and optimize their use of OpenAI Guaranteed Capacity effectively.
Strategic Planning for Capacity Commitment
One of the foundational considerations is determining the appropriate commitment length and compute volume that aligns with the organization’s AI roadmap and workload forecasts. OpenAI’s Guaranteed Capacity requires a minimum commitment of one year, with pricing tiers scaling based on both duration and volume of GPU capacity reserved. Enterprise teams must conduct comprehensive workload analysis, projecting peak and baseline demand for AI model inference and training tasks.
For example, a financial services firm planning to deploy real-time fraud detection models leveraging large language models (LLMs) may anticipate increased demand during specific market hours or regulatory reporting periods. By reserving capacity that matches these peak windows, the firm can ensure uninterrupted service while optimizing cost efficiency. Conversely, a media company with fluctuating content generation needs might opt for a larger volume commitment to cover seasonal spikes.
Enterprise teams should leverage historical API usage data, pilot projects, and predictive analytics to estimate required GPU hours accurately. The ability to adjust commitments in future contract renewals provides some flexibility, but initial underestimation can lead to performance bottlenecks, while overcommitment may result in underutilized resources and inflated costs.
Integration with Existing AI Workflows and Infrastructure
Another critical element is the seamless integration of OpenAI Guaranteed Capacity into existing AI pipelines and enterprise infrastructure. Since this offering provides dedicated GPU resources with guaranteed availability, IT and DevOps teams must plan for network configurations, security policies, and data governance compliance to accommodate the new compute environment.
OpenAI facilitates this integration through robust API compatibility with existing OpenAI service endpoints, allowing enterprises to shift workloads to guaranteed capacity with minimal code changes. However, teams should verify latency implications, data egress policies, and encryption standards to maintain enterprise-grade performance and security.
For example, enterprises operating in highly regulated sectors such as healthcare or finance will need to ensure that data processed on OpenAI’s reserved GPUs complies with HIPAA or PCI-DSS standards. This might involve implementing dedicated virtual private cloud (VPC) connections, enhanced authentication measures, and audit logging aligned with internal compliance frameworks.
Cost Management and Financial Governance
Given the commitment-based pricing model, financial planning and governance are paramount. Enterprises must incorporate the costs of reserved GPU capacity into their budgeting cycles and establish tracking mechanisms to monitor utilization versus committed capacity. This ensures that the organization achieves a favorable return on investment and avoids financial risks associated with unused reserved resources.
OpenAI offers pricing models that provide volume discounts for higher commitment tiers, incentivizing enterprises to reserve larger capacities upfront. For example, a 3-year commitment for 100+ GPUs can reduce the effective hourly rate by approximately 20-30% compared to monthly on-demand pricing. Enterprises with predictable, heavy AI workloads will benefit most from these economies of scale.
To manage costs effectively, finance and procurement teams should collaborate closely with AI practitioners to set realistic forecasts and review capacity utilization monthly or quarterly. Additionally, enterprises can negotiate contract terms that include flexibility clauses or capacity scaling options within defined limits to address evolving demand dynamics.
Operational Readiness and Support Structure
Implementing Guaranteed Capacity also requires enterprises to establish operational readiness, encompassing monitoring, incident response, and support channels. Dedicated capacity reduces the risk of API throttling or service degradation during peak demand, but enterprises must still maintain proactive monitoring to detect anomalies or performance issues promptly.
OpenAI provides enhanced enterprise support tiers aligned with Guaranteed Capacity contracts, including 24/7 technical assistance, dedicated account managers, and prioritized incident resolution. Enterprise teams should integrate these support options into their operational playbooks to minimize downtime and accelerate troubleshooting.
Furthermore, training internal teams on the nuances of managing reserved compute resources and usage best practices will enhance operational efficiency. For example, capacity planning should include regular reviews of workload patterns to identify opportunities for optimization, such as workload batching, model distillation, or off-peak scheduling.
Security and Compliance Considerations
Security remains a top priority when adopting any AI compute infrastructure. OpenAI’s Guaranteed Capacity is designed with enterprise-grade security protocols, but organizations must validate these controls against their internal standards and industry regulations.
Key considerations include data encryption at rest and in transit, access control mechanisms, identity and access management (IAM) integration, and compliance certifications such as SOC 2 Type II or ISO 27001. Enterprises should conduct thorough security assessments and penetration testing as part of the implementation process.
Additionally, enterprises handling sensitive or personally identifiable information (PII) may require data residency guarantees or mechanisms to segregate data from other tenants. OpenAI’s offering includes options for dedicated physical or virtualized hardware to meet these stringent requirements.
Summary Table: Key Implementation Considerations
| Consideration | Details | Enterprise Impact |
|---|---|---|
| Capacity Commitment | 1-year minimum; volume and duration determine pricing and availability | Requires accurate forecasting; balances cost and performance |
| Integration | API compatibility; network, security, and compliance alignment | Minimal code changes; ensures enterprise-grade security and performance |
| Cost Management | Commitment-based pricing with volume discounts; monitoring utilization | Optimizes budget allocation; prevents resource underutilization |
| Operational Readiness | Monitoring tools; enhanced support; incident response plans | Minimizes downtime; ensures SLA adherence and rapid resolution |
| Security & Compliance | Encryption, IAM, certifications, data residency options | Meets regulatory requirements; protects sensitive data |
In conclusion, enterprise adoption of OpenAI Guaranteed Capacity represents a significant evolution in strategic AI infrastructure planning. By carefully considering capacity commitments, integration nuances, cost controls, operational readiness, and security, organizations can harness this offering to enable scalable, reliable, and compliant AI deployments. This proactive approach safeguards against compute bottlenecks, aligns costs with business priorities, and positions enterprises to capitalize on AI innovation at scale.
Markos Symeonides
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.