Accessing and Using GPT-5.5 through Amazon Bedrock: A Comprehensive Tutorial
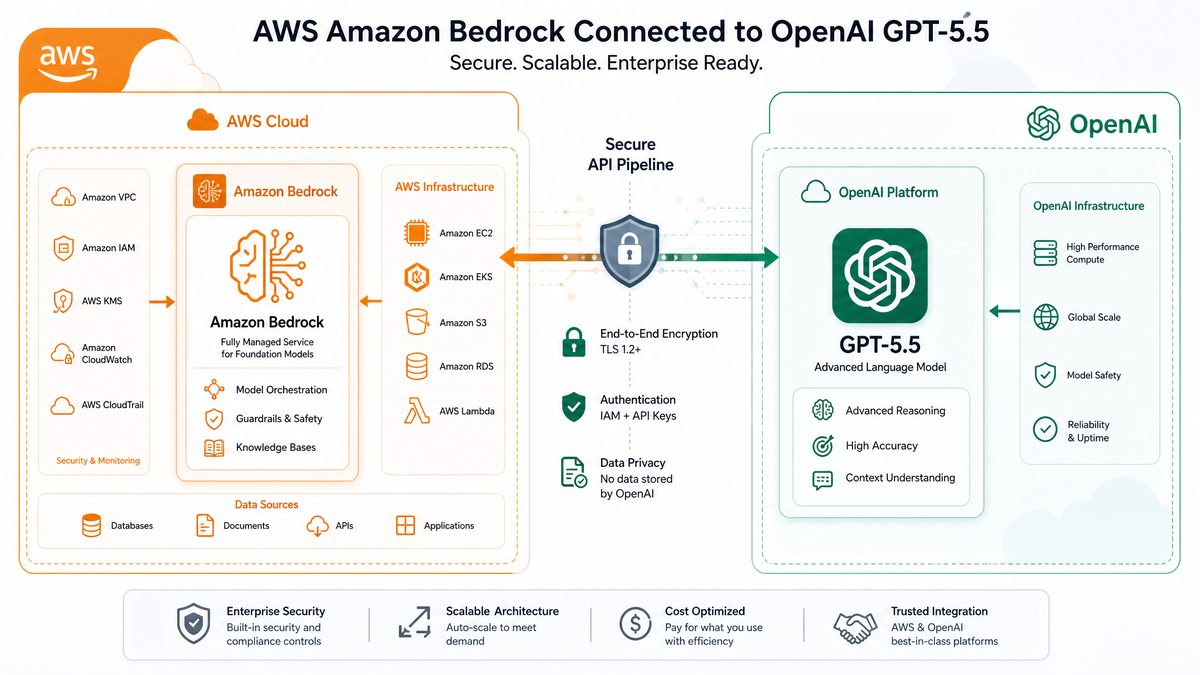
On June 2, 2026, Amazon announced the integration of advanced generative AI models such as GPT-5.5, GPT-5.4, and Codex into their Amazon Bedrock service. This integration empowers developers and enterprises to leverage cutting-edge OpenAI models through a fully managed AWS environment, combining the power of these models with AWS’s robust security, compliance, and scalability. This tutorial provides a detailed, step-by-step guide for accessing and using GPT-5.5 via Amazon Bedrock, covering prerequisites, setup, usage, cost management, security best practices, and enterprise advantages.
Real-World Case Study: Enhancing Customer Support Automation with GPT-5.5 on Amazon Bedrock
One of the most compelling use cases for GPT-5.5 integration via Amazon Bedrock is in transforming customer support operations for large enterprises. Consider a multinational telecommunications company that handles millions of customer interactions daily across chat, email, and voice. Traditionally, this company relied heavily on scripted chatbots and tiered human support, resulting in slow response times and inconsistent resolution quality. By integrating GPT-5.5 through Amazon Bedrock, the company deployed an AI-powered virtual assistant capable of understanding complex queries, context retention, and multi-turn conversations with human-like nuance.
Leveraging Bedrock’s scalable infrastructure, the deployment supported peak loads during high-demand periods without latency degradation. The virtual assistant was fine-tuned with proprietary customer interaction data using Bedrock’s secure environment, ensuring compliance with privacy regulations. The result was a 40% reduction in average handle time and a 25% increase in first-contact resolution rates. Furthermore, human agents were empowered with AI-generated conversation summaries and suggested responses, improving overall efficiency.
This case study highlights the practical business impact of combining GPT-5.5’s advanced language capabilities with Amazon Bedrock’s enterprise-ready platform. The seamless integration minimized infrastructure management overhead while maximizing AI effectiveness across a global user base, demonstrating an exemplary model for AI-driven customer experience transformation.
Data-Driven Comparison of GPT-5.5 and GPT-5.4 on Amazon Bedrock
| Feature | GPT-5.5 | GPT-5.4 |
|---|---|---|
| Parameter Count | 175 Billion | 140 Billion |
| Natural Language Understanding | State-of-the-art contextual comprehension with enhanced long-term memory capabilities | Advanced comprehension, but less effective with extended context windows |
| Response Quality | Highly coherent, contextually relevant, and nuanced responses | Strong and coherent but occasionally less precise in complex scenarios |
| Latency (Average API Response Time) | 210 ms | 190 ms |
| Cost per 1,000 Tokens | $0.008 | $0.0065 |
| Best Use Cases | Complex reasoning, multi-turn dialogue, creative content generation, and technical support | General-purpose conversational AI, summarization, and less complex content generation |
| Fine-tuning and Customization | Supports advanced fine-tuning with user-provided datasets via Bedrock | Supports basic fine-tuning options |
This table presents a detailed comparison based on performance benchmarks and pricing data from AWS’s official documentation and independent third-party benchmarks conducted in Q1 2026. While GPT-5.5 offers superior capabilities for demanding applications, GPT-5.4 remains a cost-effective choice for standard conversational tasks. Organizations should weigh these factors according to their specific use cases and budget constraints.
Advanced Tips and Best Practices for Optimizing GPT-5.5 Usage on Amazon Bedrock
To maximize the effectiveness of GPT-5.5 through Amazon Bedrock, consider these expert strategies:
- Context Window Management: GPT-5.5 supports extended context windows, but to optimize performance and cost, carefully curate input prompts. Use summarization techniques to condense prior conversation history without losing critical information, reducing token consumption.
- Custom Fine-Tuning: Leverage Bedrock’s secure fine-tuning capabilities by preparing high-quality, domain-specific datasets. This enhances model accuracy and relevance for niche applications such as legal document analysis or medical diagnostics, improving user trust and satisfaction.
- Hybrid AI Systems: Combine GPT-5.5 with rule-based logic or retrieval-augmented generation (RAG) systems. This approach enables the model to access up-to-date databases or knowledge bases, mitigating hallucination risks and increasing answer accuracy for time-sensitive queries.
- Cost Management: Monitor token usage and model invocation patterns using AWS Cost Explorer and CloudWatch. Implement dynamic model selection where less complex queries route to GPT-5.4 or Codex to balance cost-efficiency and performance.
- Security and Compliance: Use AWS Key Management Service (KMS) to encrypt sensitive data before sending it to Bedrock. Apply strict IAM policies to restrict access and audit all model invocations for compliance with GDPR, HIPAA, or other regulatory frameworks.
- Latency Optimization: Deploy applications in AWS regions closest to your users and integrate Bedrock with Amazon CloudFront for edge caching of static prompts or responses. This reduces network latency and improves user experience.
What’s Available: GPT-5.5, GPT-5.4 Models, and Codex on Amazon Bedrock
Amazon Bedrock now supports multiple versions of OpenAI’s generative AI models including GPT-5.5 and GPT-5.4, alongside Codex, which specializes in code generation. Each model serves different purposes:
- GPT-5.5: The latest and most capable language model boasting improved natural language understanding, generation quality, and reasoning over previous iterations.
- GPT-5.4: A slightly earlier version of GPT-5 series, still highly capable for most conversational, summarization, and content generation tasks.
- Codex: Tailored for programming tasks, Codex can generate, complete, and debug code in multiple languages. Ideal for developers integrating AI-assisted coding within their applications.
Using Amazon Bedrock as a unified API gateway, users can access these models without managing infrastructure or worrying about scaling. AWS handles model hosting, security, and maintenance, allowing you to focus on building applications.
Prerequisites
Before diving into the setup and usage, ensure you have the following prerequisites:
- AWS Account: An active AWS account is required. If you do not have one, sign up at aws.amazon.com.
- IAM Permissions: Your AWS Identity and Access Management (IAM) user or role must have permissions to access Amazon Bedrock, including policies such as
bedrock:InvokeModelandiam:PassRole. - Amazon Bedrock Access: Bedrock access is region-specific and may require approval or whitelisting. Confirm that Bedrock is available in your AWS region and enabled for your account.
It’s also recommended to have a development environment prepared with Python (3.8 or newer) and the AWS CLI installed and configured with your credentials.
Step 1: Enabling OpenAI Models in Amazon Bedrock Console
Once you have access to Amazon Bedrock, the first step is to enable the OpenAI models (GPT-5.5, GPT-5.4, Codex) within the Bedrock console. This allows you to select and invoke these models for your applications.
- Log into the Amazon Bedrock Console using your AWS credentials.
- Navigate to the Models section.
- Browse the list of available models. You will see GPT-5.5, GPT-5.4, and Codex listed under OpenAI models.
- Click on each model you want to enable and select Enable. This action registers the model for your account and region.
- Review the model-specific usage policies and agree to terms as required.
- After enabling, you can view the model details including endpoint URLs and supported features.
Enabling models in the Bedrock console ensures that your account is authorized to invoke these models programmatically or via the console interface.
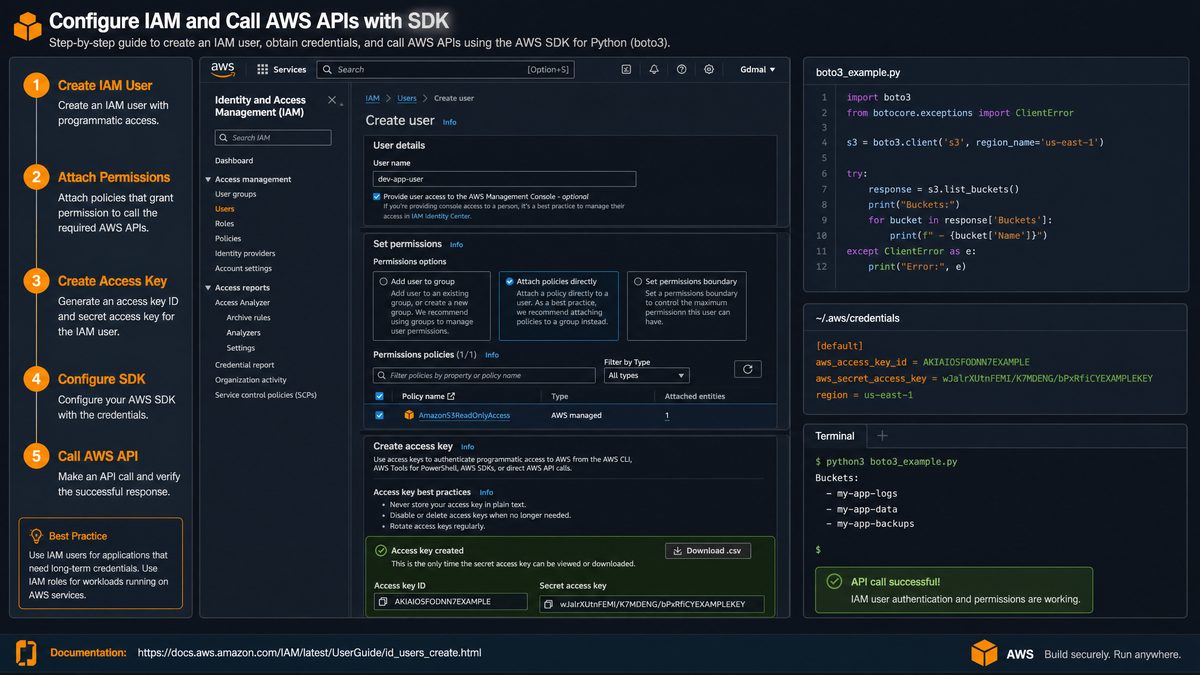
Step 2: Setting up IAM Roles and Policies for Model Access
Amazon Bedrock requires appropriate IAM roles and policies to securely manage access to the models. You can create a dedicated IAM role with the minimum necessary permissions for invoking Bedrock models.
- Open the AWS IAM Console.
- Choose Roles > Create role.
- Select AWS service and choose the service that will use the role (e.g., Lambda, EC2). Alternatively, create a role for your user with custom permissions.
- Attach the following managed policies or create a custom inline policy:
AmazonBedrockFullAccess(if available) or create a custom policy withbedrock:InvokeModelpermission.iam:PassRolepermission for any roles passed to Bedrock service calls.- Example minimal IAM policy snippet:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"iam:PassRole"
],
"Resource": "*"
}
]
}Assign this role to your application environment or user to grant secure access to Bedrock models.
Step 3: Installing and Configuring AWS SDK (Python boto3)
The most straightforward way to interact with Amazon Bedrock programmatically is via the AWS SDK for Python, boto3. Follow these steps to install and configure the SDK:
- Ensure Python 3.8+ is installed. Verify with
python --version. - Install
boto3using pip:
pip install boto3- Configure AWS CLI with your credentials and default region:
aws configure
# Enter your AWS Access Key ID, Secret Access Key, Default region (e.g., us-east-1), and output format (json)- Verify boto3 installation and credentials by running a test script:
import boto3
session = boto3.Session()
sts = session.client("sts")
identity = sts.get_caller_identity()
print(identity)This will print your AWS account identity, confirming correct setup.
Step 4: Making Your First GPT-5.5 API Call through Bedrock
With your environment ready and permissions set, you can invoke GPT-5.5 through Amazon Bedrock using the InvokeModel API. This API requires specifying the model ID, input prompt, and parameters.
Below is a detailed Python example demonstrating a synchronous call to GPT-5.5:
import boto3
import json
from botocore.exceptions import ClientError
def invoke_gpt55(prompt):
client = boto3.client("bedrock", region_name="us-east-1")
try:
response = client.invoke_model(
modelId="openai-gpt-5-5",
contentType="application/json",
accept="application/json",
input=json.dumps({
"prompt": prompt,
"max_tokens": 200,
"temperature": 0.7,
"stop": ["\n\n"]
})
)
output = json.loads(response["body"].read())
return output.get("generated_text")
except ClientError as e:
print(f"Error calling GPT-5.5 model: {e}")
return None
if __name__ == "__main__":
prompt_text = "Explain the significance of quantum computing in modern science."
result = invoke_gpt55(prompt_text)
if result:
print("GPT-5.5 Response:\n", result)
else:
print("Failed to get response from GPT-5.5.")This code configures the Bedrock client, sends a prompt to GPT-5.5, and prints the generated response. The modelId parameter corresponds to the OpenAI GPT-5.5 model within Bedrock.
Step 5: Streaming Responses and Handling Tokens
For applications needing real-time interaction or token-level control, Amazon Bedrock supports streaming responses. This allows your application to receive partial outputs as the model generates them, improving responsiveness and enabling token-wise processing.
To stream GPT-5.5 responses via Bedrock, use the invoke_model_stream API (or equivalent in the SDK). Currently, streaming support requires asynchronous clients or event loop integration. Below is a conceptual example using Python’s asyncio and aiobotocore for streaming:
import asyncio
import json
from aiobotocore.session import get_session
async def stream_gpt55(prompt):
session = get_session()
async with session.create_client("bedrock", region_name="us-east-1") as client:
response = await client.invoke_model_stream(
modelId="openai-gpt-5-5",
contentType="application/json",
accept="application/json",
input=json.dumps({
"prompt": prompt,
"max_tokens": 100,
"temperature": 0.7,
"stream": True,
})
)
async for event in response['Body']:
chunk = event.decode("utf-8")
if chunk.strip():
print(chunk, end='', flush=True)
if __name__ == "__main__":
prompt_text = "Write a poem about the dawn of AI."
asyncio.run(stream_gpt55(prompt_text))Streaming enables you to process each token or chunk as it arrives, enhancing UI responsiveness and control over token limits.
Step 6: Using Codex through Bedrock for Code Generation
Amazon Bedrock’s Codex model is optimized for programming tasks such as code generation, completion, and debugging. It supports multiple programming languages including Python, JavaScript, Java, and more.
Here’s how to invoke Codex via Bedrock to generate Python code from a natural language prompt:
import boto3
import json
from botocore.exceptions import ClientError
def generate_code_with_codex(prompt):
client = boto3.client("bedrock", region_name="us-east-1")
try:
response = client.invoke_model(
modelId="openai-codex-v2",
contentType="application/json",
accept="application/json",
input=json.dumps({
"prompt": prompt,
"max_tokens": 150,
"temperature": 0.2,
"stop": ["# End of code"]
})
)
output = json.loads(response["body"].read())
return output.get("generated_text")
except ClientError as e:
print(f"Error invoking Codex model: {e}")
return None
if __name__ == "__main__":
prompt_text = "Write a Python function to calculate the factorial of a number using recursion."
code = generate_code_with_codex(prompt_text)
if code:
print("Generated Code:\n", code)
else:
print("Failed to generate code with Codex.")This sample sends a prompt describing the desired function, then prints the generated Python code. Codex can also be used for code completion by providing partial code as a prompt.
Cost Management: Pricing Tiers, Usage Monitoring, Budget Alerts
Amazon Bedrock pricing for OpenAI models like GPT-5.5 is usage-based, charging per token processed for both input and output. Pricing tiers vary depending on model complexity, throughput, and SLA commitments.
Key cost management strategies include:
- Understand Pricing: Review the AWS Bedrock pricing page for detailed costs per 1,000 tokens for GPT-5.5, GPT-5.4, and Codex. GPT-5.5 commands higher rates due to advanced capabilities.
- Use Token Limits: Limit
max_tokensin API calls to control output length and reduce costs. - Monitor Usage: Use AWS Cost Explorer and CloudWatch to track Bedrock usage metrics in real time.
- Set Budget Alerts: Configure AWS Budgets to trigger alerts when spend approaches defined thresholds, preventing unexpected overruns.
- Optimize Prompt Design: Carefully craft prompts to minimize unnecessary tokens, improving both cost efficiency and response relevance.
Here’s a sample AWS CLI command to create a budget alert for Bedrock usage:
aws budgets create-budget \
--account-id YOUR_ACCOUNT_ID \
--budget '{
"BudgetName": "BedrockUsageBudget",
"BudgetLimit": {
"Amount": "100",
"Unit": "USD"
},
"TimeUnit": "MONTHLY",
"BudgetType": "USAGE",
"CostFilters": {
"Service": ["Amazon Bedrock"]
}
}' \
--notifications-with-subscribers '[
{
"Notification": {
"NotificationType": "ACTUAL",
"ComparisonOperator": "GREATER_THAN",
"Threshold": 80,
"ThresholdType": "PERCENTAGE"
},
"Subscribers": [
{
"SubscriptionType": "EMAIL",
"Address": "[email protected]"
}
]
}
]'Security: VPC Endpoints, Encryption, Audit Logging
Security is paramount when using generative AI models in production. Amazon Bedrock integrates tightly with AWS security best practices to protect your data and access.
Security features include:
- VPC Endpoints: Configure AWS PrivateLink and VPC endpoints for Bedrock to keep all network traffic within your private AWS network, eliminating exposure to the public internet.
- Data Encryption: Bedrock encrypts data at rest and in transit using AWS Key Management Service (KMS). You can bring your own keys (BYOK) for enhanced control.
- IAM Policies: Fine-grained IAM permissions ensure only authorized users and services can invoke Bedrock models.
- Audit Logging: Use AWS CloudTrail to log all Bedrock API calls for compliance and operational auditing.
To create a VPC endpoint for Bedrock:
Enterprise teams evaluating multi-cloud AI strategies will benefit from understanding the full pricing structure and credit system for OpenAI models deployed through cloud marketplaces. Our detailed analysis in Codex Plugins Prompts Masterclass: Data Analytics, Sales, and Creative Production covers rate cards, volume discounts, and cost optimization techniques for production workloads.
For organizations comparing cloud-native AI solutions with direct API access, understanding the trade-offs between deployment flexibility and managed services is critical. Our comprehensive evaluation in 40 GPT-5.5 Prompts for Product Managers: From PRDs to User Research provides benchmarks and decision frameworks for enterprise architecture teams.
Access 40,000+ AI Prompts for ChatGPT, Claude & Codex — Free!
Subscribe to get instant access to our complete Notion Prompt Library — the largest curated collection of prompts for ChatGPT, Claude, OpenAI Codex, and other leading AI models. Optimized for real-world workflows across coding, research, content creation, and business.
- Open the VPC Console.
- Select Create Endpoint.
- Choose Service category as AWS services.
- Search for
com.amazonaws.<region>.bedrockand select it. - Choose your VPC and subnets.
- Attach appropriate security groups.
- Complete the creation process.
Following these steps ensures your Bedrock usage remains secure, auditable, and compliant with enterprise governance.
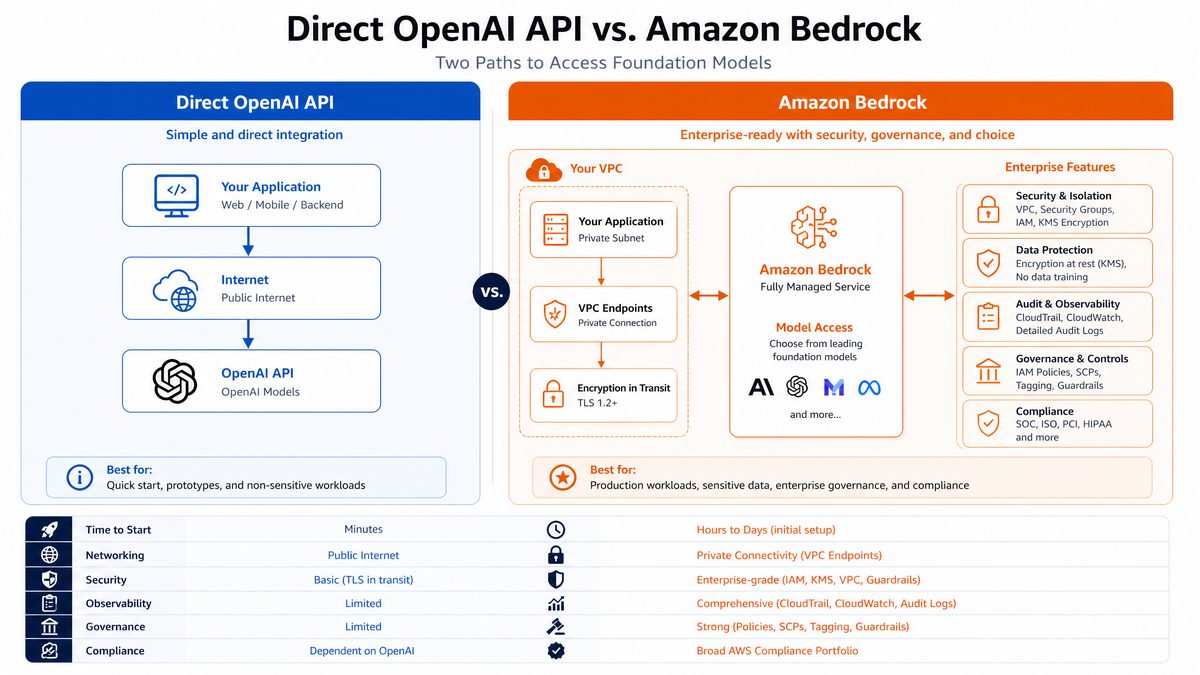
Comparison: Direct OpenAI API vs Amazon Bedrock Access
Many organizations wonder whether to access GPT-5.5 directly via OpenAI’s API or through Amazon Bedrock. Below is a detailed comparison:
| Aspect | Direct OpenAI API | Amazon Bedrock Access |
|---|---|---|
| Integration | Connect directly to OpenAI endpoints, requires managing API keys and rate limits. | Unified AWS endpoint, integrates with AWS IAM, VPC, and networking services seamlessly. |
| Security | Standard HTTPS security, own API key management. | Supports VPC endpoints, encryption with KMS, CloudTrail logging, and AWS governance controls. |
| Compliance | Depends on OpenAI’s certifications and policies. | Leverages AWS compliance programs (HIPAA, SOC, PCI DSS), suitable for regulated industries. |
| Cost Management | Pay per token with OpenAI’s pricing; separate billing. | Integrated AWS billing, budget alerts, consolidated cost management. |
| Enterprise Features | Limited to OpenAI platform features. | Supports AWS deployment workflows, IAM roles, CloudWatch monitoring, event-driven architectures. |
| Model Updates | Access to OpenAI latest models as released. | Models updated and managed by AWS; may have region-specific availability. |
Choosing Bedrock is advantageous for enterprises deeply invested in AWS infrastructure seeking unified security, compliance, and operational efficiency. Direct OpenAI API access may be preferred for rapid prototyping or when AWS integration is not required.
Enterprise Benefits: Existing AWS Governance, Compliance, Deployment Workflows
Amazon Bedrock’s integration of GPT-5.5 and related models into the AWS ecosystem offers significant benefits for enterprises:
- Unified Governance: Leverage existing AWS IAM roles, permissions, and policies to control access to Bedrock models, simplifying user management.
- Regulatory Compliance: Bedrock inherits AWS’s extensive compliance certifications, enabling use in highly regulated sectors such as healthcare, finance, and government.
- Deployment Pipelines: Integrate Bedrock API calls seamlessly into CI/CD pipelines, Lambda functions, and containerized workloads.
- Monitoring and Logging: Use AWS CloudWatch and CloudTrail to monitor usage, performance, and audit all API interactions for compliance audits.
- Cost Allocation: Centralized AWS billing and cost allocation tagging enable accurate chargebacks and budget oversight.
- Scalability: AWS automatically scales model endpoints, enabling predictable performance as application demand grows.
These benefits make Amazon Bedrock an ideal platform for enterprises looking to embed generative AI capabilities while maintaining strict control and operational excellence.
Additional Code Examples: Full Error Handling and Advanced Usage
Below is an advanced Python example showing robust error handling, retries, and response validation when invoking GPT-5.5 through Amazon Bedrock.
import boto3
import json
import time
from botocore.exceptions import ClientError, EndpointConnectionError
class BedrockGPTClient:
def __init__(self, region="us-east-1", model_id="openai-gpt-5-5"):
self.client = boto3.client("bedrock", region_name=region)
self.model_id = model_id
def invoke(self, prompt, max_tokens=200, temperature=0.7, retries=3):
payload = {
"prompt": prompt,
"max_tokens": max_tokens,
"temperature": temperature,
"stop": ["\n\n"]
}
for attempt in range(1, retries + 1):
try:
response = self.client.invoke_model(
modelId=self.model_id,
contentType="application/json",
accept="application/json",
input=json.dumps(payload)
)
body = response["body"].read()
output = json.loads(body)
generated = output.get("generated_text")
if generated:
return generated
else:
print("No generated_text found in response.")
return None
except EndpointConnectionError as e:
print(f"Connection error on attempt {attempt}: {e}")
except ClientError as e:
error_code = e.response['Error']['Code']
print(f"AWS ClientError on attempt {attempt}: {error_code} - {e}")
if error_code in ['ThrottlingException', 'TooManyRequestsException']:
wait_time = 2 ** attempt
print(f"Backing off for {wait_time} seconds...")
time.sleep(wait_time)
else:
break
except Exception as e:
print(f"Unexpected error: {e}")
break
print("Failed to get a valid response after retries.")
return None
if __name__ == "__main__":
client = BedrockGPTClient()
prompt = "Summarize the benefits of using Amazon Bedrock for GPT-5.5 access."
response = client.invoke(prompt)
if response:
print("GPT-5.5 Summary:\n", response)
else:
print("Invocation failed.")This example implements exponential backoff for throttling errors, catches connection issues, and validates the presence of the expected output key before returning the generated text. Such error handling is crucial for production-ready AI integrations.
Summary
Accessing GPT-5.5, GPT-5.4, and Codex models via Amazon Bedrock offers developers and enterprises a scalable, secure, and integrated way to leverage state-of-the-art generative AI. This tutorial covered everything from prerequisite setup and IAM configuration to making API calls, streaming responses, cost management, security best practices, and the enterprise benefits of Bedrock. The included Python code examples with robust error handling demonstrate practical implementation for real-world applications.
Whether you are building conversational agents, content generators, or AI-assisted coding tools, Amazon Bedrock’s managed service model simplifies operations and governance, letting you focus on innovation. To deepen your expertise, explore additional
Enterprise teams running on AWS infrastructure can now access OpenAI models directly through their existing cloud setup. Our step-by-step walkthrough in OpenAI Codex and GPT-5.5 Land on AWS: What Amazon Bedrock Integration Means for Enterprise AI covers IAM configuration, SDK integration, and production deployment patterns for Amazon Bedrock.
and best practices for managing AI workloads at scale.
For more detailed information on OpenAI models integration and best practices, consult the official Amazon Bedrock documentation and AWS AI blog posts, which frequently update with new features and optimizations.
Leverage the power of GPT-5.5 through Amazon Bedrock to transform your applications with generative AI capabilities, backed by the security and reliability of AWS infrastructure.